


搜索到
15
篇与
的结果
-
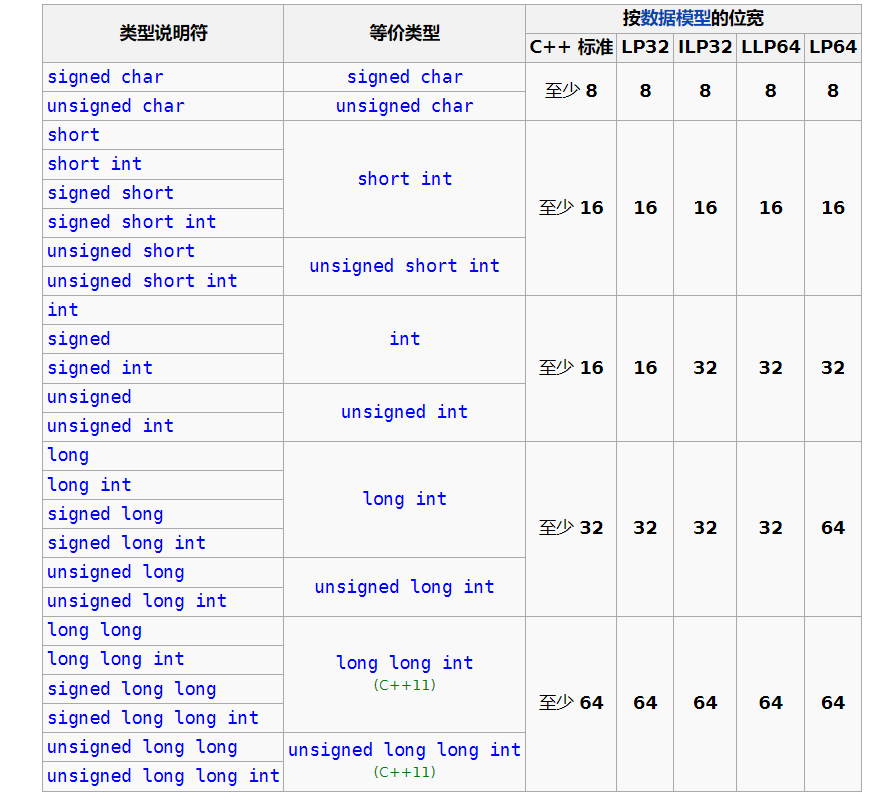
 CPP基础教程 基本数据类型C++的基本数据类型有int, char, bool, short, long, long long, float, double, void, unsinged int(short, long long...), std::nullptr_t,具体可查types这么多都要记住?nullptr_t其实不用,其他的是的,不过这里给个建议,你只需要记住int, char, bool, long long, double, float, void这几个即可如果你需要无符号数那么在他们前边加上unsigned就好了。接下来对他们做个分类:整数浮点数intfloatlong longdoubleshort char和bool存储起来是按整数存的但是他们的作用并不是储存整数,所以我并没有把他们放在上边的表格里,char是字符类型可以存储ascii码表里所有的字符,bool是布尔类型用来存储true或false(在c++中我们判断条件应该用bool而不是整数01,当然他们会被转成bool类型,所以使用还是不影响的)接下来介绍一下它们的大小,直接上图这里有一个误区就是你在学习c语言课的时候可能老师跟你讲这个类型具体是多少多少字节,但是C++标准只规定了最少应该是几字节(上图显示为bit)并没有说具体就应该是几字节,所以在某些系统中你可以看到int居然是2字节?!什么这里short和int相同?long怎么在这是64位在那就32位了,这都是因为它们的大小是实现定义的,只规定了至少应该是多少位,而不是一定。(拓展:在以后开发时如果你不想因为数据大小造成困扰,那么就使用int_16, int_32, int_64类型的数据,这样就不用担心数据位宽不符合了)接下来就是他们能表示数的范围,对有符号整数来说N位有符号整数的最小保证范围从-(2^(N-1) - 1)到(2^(N-1) - 1),浮点数因为存储格式与整数不同,所以前边的结论并不适用于浮点数,浮点数存储结构大概是符号位 偏移 数据,这里我们假设符号位是0也就是正数,偏移是10(2),数据是101(2进制),那么这个数就是 110.1(2进制)也就是6.5,数据前补1,浮点从.101向后移动两位,所以浮点数可以表示远大于它的相同位宽的整数,但是数据会丢失精度,如果你需要高精度计算,千万别用浮点数这里还有一个误区就是char的表示范围(内部储存的整数)这也是实现定义的,有可能是-128到127也可能是0到255输入输出在c语言中标准输入输出就是scanf、printf,c++也支持这两个函数,不过更c++的写法是输入输出流即使用cin、cout,相比较来说各有优劣,这两套的区别就在格式化,看你是否需要格式化输入输出来选择合适的方法。cin、cout的用法如下#include <iostream> // 包含cin cout的头文件 using namespace std; // 这里是跟命名空间有关,这里先不讲 int main() { int a; cin >> a; // 这里>>是流操作符不是大于大于,代表将输入流中的数据传给a cout << a; // <<也是流操作符,这样你就可以看出流操作的方向,上边是cin流向a,这里是a流向cout return 0; }运行之后你输入几就会再输出几,如果你需要一次性输入更多变量(不需要格式化的,每个变量以空格或者回车结尾的),那么就可以直接这么写#include <iostream> using namespace std; int main() { int a, b; char c; cin >> a >> b >> c; // 输入 a b c cout << a << b << c; // 输出 a b c return 0; }还有一点,由于cin这套会和scanf这套同步缓冲池,所以cin这套的速度比scanf这套慢一倍,想要cin达到同样的性能可以直接解绑#include <iostream> int main() { std::ios::sync_with_stdio(false); std::cin.tie(0); // 上边两句就是解绑,使用之后你用cin读取的数据就不能通过printf输出了也就是不能混用了 }数组数组是一段相同类型的元素的集合,它们在逻辑上是连续的,在内存中也是连续的,数组的声明方式为类型 数组名[数组大小],例如我需要一个长度为10的int类型的叫arr数组,那么声明时就写int arr[10];,这个数组占的空间就是sizeof(int) * 10(这个sizeof 是关键字可以求后边类型所占字节),当我们需要访问数组中的某一个元素的时候,就需要通过下标访问,数组的下标是从0开始的,也就是说第一个元素的下标为0而不是1,第二个是1,以此类推,c/c++在你访问数组元素时并不会检查下标是否合理(在不在数组范围内),所以在操作数组时你需要严格控制操作的下标范围。当你需要一些类型相同的元素的时候就可以使用数组,比如说我要输入10个元素,如果你不会用数组的话那你可能会写int a, b, c, d, e...; cin >> a >> b >> c...;这很明显声明起来并不方便,10个元素还好如果是10000个呢?不能一个一个起名吧,这时候就可以使用数组int a[10000];搞定。不过这个时候输入输出就成了大问题,那么接下来就需要与循环结合起来,才能充分发挥数组的功能数组可以是多维的,例如二维数组可以声明为int arr[10][10];这样就得到了长10宽10的二维数组(不过他们在内存上还是连续的等同于int arr2[100]),当你需要访问第一行第二列的元素时就使用下标arr0;三维甚至更高维的数组同理循环选择结构C++的循环选择与C语言并没有区别,选择会用到if else switch,循环则有for、while、do while。用法如下:if (条件) 条件为true执行语句 else 条件为false执行语句else并不是必须的,看你自己需求,if和else后边都只接一条语句,需要接更多语句就需要使用大括号包围起来int a; cin >> a; if (a == 10) a = 5; cout << "a = 10\n"; else cout << "a != 10\n";思考一下上边的语句是否正确。看出问题了吗?没错这里的if后边其实只接了a = 5;这一条,else会找不到它对应的if,所以这时候会编译错误,去掉else之后cout << "a = 10\n";这句则是一定执行的所以千万要记得if else for while do后边接多个语句时要加大括号,原因可以看作用域这部分。所以上边代码的正确写法应该是:int a; cin >> a; if (a == 10) { a = 5; cout << "a = 10\n"; } else { cout << "a != 10\n"; } // 养成良好习惯,一句也加大括号有的人可能认为else if也是关键字什么的,其实不是,else if就是else语句后接了个if语句,本质上为if (condition) { blabla... } else { if () { blabla... } }for的使用形式为for(刚进入循环时执行一次的语句; 循环执行条件,为true才可以继续执行; 一次循环结束后执行的语句),没什么好讲的,直接上代码!int a[100]; for (int i = 0; i < 100; i++) { cin >> a[i]; } for (int i = 0; i < 100; i++) { cout << a[i]; }上边的代码做了什么事呢?首先是申明了一个大小为100的数组,之后在循环开始时申明了一个变量 i 并初始化为0,再判断i < 100为true,之后开始执行循环也就是cin >> a[i],循环体内所有语句执行完毕,自动执行i++,让i = 1...while的用法很简单,只有一个判断条件while(条件),条件为真则继续执行,使用while实现与上边for相同功能的写法是这样的:int a[100]; { int i = 0; while (i < 100) { cin >> a[i]; i++; } } { int i = 0; while (i < 100) { cout << a[i]; i++; } }为什么用了大括号呢,还是跟作用域有关,总之,while只有在条件为true时才继续执行,且不能像for一样在开始执行一次第一个‘;’前的语句dowhile和while类似,不同的是dowhile保证循环体代码至少执行一次,它是执行之后才判断条件真假,while和for则是一开始就判断do { cout << "13 * 4"; } while(false); // 记得不能忘了这个分号尽管上边的语句条件为false,但是仍然会输出“13 * 4”,这就是do while的特别之处continue break有的时候我们在循环体中可能想达到某些条件就提前退出或者不继续执行下边的代码,这时候就要用到continue、break控制了,continue的作用是跳过下边的代码,执行到循环尾也就是while (true) { a; continue; d; b; } <-这个地方 // 这是个死循环之后开始下一次循环,break是直接退出循环while (true) { a; break; d; b; } // 退出循环,不是死循环执行a之后就不会执行db了。那么实战中一般会怎么使用呢?,比如从0到100,输出所有奇数int a = 0; while (true) { if (a > 100) { break; } if (a % 1 == 0) { continue; } cout << a << ' '; }上边的例子即使用了break也使用了continue,你可以一步一步调试看看代码执行时发生了什么switch的功能有点鸡肋,你必须穷举所有结果,一般switch都跟break一起用,这就是为什么我在这才写switch,switch后边跟条件,但是与if不同,它不是判断真假,而是将条件进行匹配,这用到了另一个关键字caseint a; cin >> a; switch (a) { case 12: case 14: cout << "wow!\n"; break; default : cout << "emm..\n"; }上边的代码在输入12或者14时候会输出wow,其他情况都是emm..,这个例子同样表明不是所有case后都得跟break,如果不跟的话就会继续延顺下去,也就是说下边这种情况输入12时会输出good haha,输入14就是hahaint a; cin >> a; switch (a) { case 12: cout << "good " case 14: cout << "haha\n"; break; default : cout << "emm..\n"; }指针终于到了指针了,首先我要说明:指针一点也不难!指针也只是一个变量,它的标志就是类型中带有一个 * 号,比如int*就是int类型的指针,它可以指向一块类型为int的变量的内存,记住指针保存的就是地址就行了,这里不能理解的话那么我们抽象一下你是一个人,你叫做A,用代码表示就是人 A,你在这个地球上,你的位置(地址)是唯一的,因为不可能有人跟你重合,我们可以通过&得到你当前的位置比如经度117.42 纬度19.24 海拔345米,我们可以用一个叫人* pos = &A;来保存这个数据,同理,在程序运行时,每个变量也会有一个唯一的地址,这里不展开讨论,有兴趣的话自行了解,这个地址根据系统不同得到的结果也不同,64位系统就是64位数字32位系统就是32位数字,这个地址一定是整数,且是不会变的,我们可以通过这个地址找到这个变量的位置读取它或者修改它。int a{}; // a = 0 int *b = &a; // b = a 的地址 *b = 5; // a = 5,通过解引用修改b指向的那块地址的数据(a)的值 int c = *b; // c = 5,通过解引用读取b指向的a的值记住指针是一个变量,它保存的值是其他变量的地址,通过解引用就可以访问指针指向的变量。(*b)此刻就是a还有一点是数组与指针之间的关系,很多人都会搞错,先给出结论:数组和指针是完全不同的两个东西,唯一的关系就是数组可以退化成指针。int arr[100]; int* p = arr; // 也就是说,这句的意思不是数组和指针一样所以可以给p赋值arr,而是arr在这里退化成了指针,arr的地址储存在了p中 // 最简单的证明方法就是你不能给一个数组赋值指针,下边这句是不允许的 int* p2; int arr2[100] = p2;一个完整的数组包含了长度信息,而指针是不会包含这部分信息的。不过值得一提的是你可以对指针进行中括号运算。int arr[100]; int* p = arr; p[n] == arr[n] // 这个式子是恒成立的中括号运算本质上是通过指针 + 偏移计算元素位置,就是 p[n] 和 *(p + n)是等价的,所以你可以写出这样的代码0["ABC"]得到的结果是A。最后一小点,c++中的空指针默认为nullptr而不是NULLnullptr就是最开始提到的std::nullptr类型的数据,在写c++代码时,如果你要表示空指针,请用nullptr而不是NULL或者0。函数函数的作用是增加代码复用,因为有的句子你可能会重复写很多次,假如有的功能要几百行几千行,你又需要多次使用该功能,总不能一遍又一遍写吧,哪怕复制粘贴也是需要改一些参数的,还是很麻烦,所以这时候就可以通过函数包装一下。一个完整的函数需要 返回值类型 函数名 (函数参数) { 执行代码; 返回值;(返回类型为void时不需要返回值,但是可以通过return提前结束函数执行)}举个简单的例子int add(int a, int b) { return a + b; } int main() { std::cout << add(3, 4); // 输出7 }C++的函数可以通过修改参数进行重载,以下是一些例子(1) int a() { ... return ...; } // 先声明函数a (2) double a() { } // 错误,修改返回值类型不能重载函数 (3) int a(int x) { ... } // 没问题,这个函数a比(1)多了一个int参数 (4) double a(double x) { ... } // 没问题,(4)和(3)的参数类型不同 (5) double a(int x) { ... } // 错误,参数类型和(3)冲突 (6) int a(int x, double y) { ... } // 没问题 (7) int a(double x, int y) { ... } // 没问题,和(6)不冲突,参数虽然数量一样,但是对应参数类型不同重载函数之后在执行函数时程序会选择最匹配的函数执行(1) int a(int x) { ... } int main() { a(3.14) // 可以执行a函数,但是3.14会被转为整型也就是 3 } ------------------------------------------------------ (2) int a(int x) { ... return 1; } int a(double x) { ... return 2; } int main() { a(3.14); // 返回2 a(3); // 返回1 }函数的参数是复制进去的,所以如果你需要修改一些数据,是不能通过直接传参完成的void fun(int a) { a = 10; } int main() { int b = 89; fun(b); /** b这时候还是89,不会在fun中被修改为10 这是因为在调用fun函数时,我们执行的操作是将b赋值给a,这时候a就是一个和b完全无关的变量 对a执行任何操作都与b无关 **/ }想要修改b为10,我们有两种做法,第一种做法是通过指针来修改,如我前文所说,通过指针可以找到变量本身,这样我们修改的就是我们想要的变量,而不是一个通过复制得到的变量。void fun(int* a) { *a = 10; } int main() { int b = 89; fun(&b); // ok, 现在b = 10 }开始讲第二种方法前,我们再引入一个新的概念引用,引用说简单点就是变量的别名,小花有一个别名叫张三,有的人喜欢叫小花,有的人喜欢叫张三,虽然名字不一样,但是表示的还是同一个人,引用就是这样的,你可以通过给一个变量起别名来访问该变量。引用的声明方式是在类型后加一个&(&作用真多...)int a; int &b = a; // b是a的别名 int &c = a; // c、b都是a的别名 int &d; // 错误,引用在申明时就得初始化!!! b = 10; // a,b,c都等于10引用作为函数参数时,可以直接修改原数据void fun(int &a) { a = 10; } int main() { int a; fun(a); // a = 10 }作用域与生命周期这一部分我觉得是非常简单的,总结起来就一句话一对大括号内的内容属于一个作用域,变量的生命周期从申明开始到离开大括号结束,全局变量、静态变量生命周期贯穿整个程序。举例子:1. void f() { 2. int a; 3. int b; 4. { 5. int c; 6. std::cin >> c; 7. } 8. std::cin >> c; 9. int c; 10. }想想上边的代码有问题吗?如果有那是第几行?这个函数中我们声明了两次变量c,错误点在这吗?当然不是。我们把1-10行叫作用域1,4-7行叫作用域2,我们先在作用域2声明了c并使用cin输入c。在离开作用域2之后又再一次尝试输入变量c,这时候就有问题了,离开了作用域2,变量c的生命周期结束,这时候在cin时不可以的,因为不知道c是啥,所以错误点在第8行。变量ab的生命周期一直到函数执行完毕。你可以自己写一些例子实验一下,亲自体会一下生命周期、作用域。
CPP基础教程 基本数据类型C++的基本数据类型有int, char, bool, short, long, long long, float, double, void, unsinged int(short, long long...), std::nullptr_t,具体可查types这么多都要记住?nullptr_t其实不用,其他的是的,不过这里给个建议,你只需要记住int, char, bool, long long, double, float, void这几个即可如果你需要无符号数那么在他们前边加上unsigned就好了。接下来对他们做个分类:整数浮点数intfloatlong longdoubleshort char和bool存储起来是按整数存的但是他们的作用并不是储存整数,所以我并没有把他们放在上边的表格里,char是字符类型可以存储ascii码表里所有的字符,bool是布尔类型用来存储true或false(在c++中我们判断条件应该用bool而不是整数01,当然他们会被转成bool类型,所以使用还是不影响的)接下来介绍一下它们的大小,直接上图这里有一个误区就是你在学习c语言课的时候可能老师跟你讲这个类型具体是多少多少字节,但是C++标准只规定了最少应该是几字节(上图显示为bit)并没有说具体就应该是几字节,所以在某些系统中你可以看到int居然是2字节?!什么这里short和int相同?long怎么在这是64位在那就32位了,这都是因为它们的大小是实现定义的,只规定了至少应该是多少位,而不是一定。(拓展:在以后开发时如果你不想因为数据大小造成困扰,那么就使用int_16, int_32, int_64类型的数据,这样就不用担心数据位宽不符合了)接下来就是他们能表示数的范围,对有符号整数来说N位有符号整数的最小保证范围从-(2^(N-1) - 1)到(2^(N-1) - 1),浮点数因为存储格式与整数不同,所以前边的结论并不适用于浮点数,浮点数存储结构大概是符号位 偏移 数据,这里我们假设符号位是0也就是正数,偏移是10(2),数据是101(2进制),那么这个数就是 110.1(2进制)也就是6.5,数据前补1,浮点从.101向后移动两位,所以浮点数可以表示远大于它的相同位宽的整数,但是数据会丢失精度,如果你需要高精度计算,千万别用浮点数这里还有一个误区就是char的表示范围(内部储存的整数)这也是实现定义的,有可能是-128到127也可能是0到255输入输出在c语言中标准输入输出就是scanf、printf,c++也支持这两个函数,不过更c++的写法是输入输出流即使用cin、cout,相比较来说各有优劣,这两套的区别就在格式化,看你是否需要格式化输入输出来选择合适的方法。cin、cout的用法如下#include <iostream> // 包含cin cout的头文件 using namespace std; // 这里是跟命名空间有关,这里先不讲 int main() { int a; cin >> a; // 这里>>是流操作符不是大于大于,代表将输入流中的数据传给a cout << a; // <<也是流操作符,这样你就可以看出流操作的方向,上边是cin流向a,这里是a流向cout return 0; }运行之后你输入几就会再输出几,如果你需要一次性输入更多变量(不需要格式化的,每个变量以空格或者回车结尾的),那么就可以直接这么写#include <iostream> using namespace std; int main() { int a, b; char c; cin >> a >> b >> c; // 输入 a b c cout << a << b << c; // 输出 a b c return 0; }还有一点,由于cin这套会和scanf这套同步缓冲池,所以cin这套的速度比scanf这套慢一倍,想要cin达到同样的性能可以直接解绑#include <iostream> int main() { std::ios::sync_with_stdio(false); std::cin.tie(0); // 上边两句就是解绑,使用之后你用cin读取的数据就不能通过printf输出了也就是不能混用了 }数组数组是一段相同类型的元素的集合,它们在逻辑上是连续的,在内存中也是连续的,数组的声明方式为类型 数组名[数组大小],例如我需要一个长度为10的int类型的叫arr数组,那么声明时就写int arr[10];,这个数组占的空间就是sizeof(int) * 10(这个sizeof 是关键字可以求后边类型所占字节),当我们需要访问数组中的某一个元素的时候,就需要通过下标访问,数组的下标是从0开始的,也就是说第一个元素的下标为0而不是1,第二个是1,以此类推,c/c++在你访问数组元素时并不会检查下标是否合理(在不在数组范围内),所以在操作数组时你需要严格控制操作的下标范围。当你需要一些类型相同的元素的时候就可以使用数组,比如说我要输入10个元素,如果你不会用数组的话那你可能会写int a, b, c, d, e...; cin >> a >> b >> c...;这很明显声明起来并不方便,10个元素还好如果是10000个呢?不能一个一个起名吧,这时候就可以使用数组int a[10000];搞定。不过这个时候输入输出就成了大问题,那么接下来就需要与循环结合起来,才能充分发挥数组的功能数组可以是多维的,例如二维数组可以声明为int arr[10][10];这样就得到了长10宽10的二维数组(不过他们在内存上还是连续的等同于int arr2[100]),当你需要访问第一行第二列的元素时就使用下标arr0;三维甚至更高维的数组同理循环选择结构C++的循环选择与C语言并没有区别,选择会用到if else switch,循环则有for、while、do while。用法如下:if (条件) 条件为true执行语句 else 条件为false执行语句else并不是必须的,看你自己需求,if和else后边都只接一条语句,需要接更多语句就需要使用大括号包围起来int a; cin >> a; if (a == 10) a = 5; cout << "a = 10\n"; else cout << "a != 10\n";思考一下上边的语句是否正确。看出问题了吗?没错这里的if后边其实只接了a = 5;这一条,else会找不到它对应的if,所以这时候会编译错误,去掉else之后cout << "a = 10\n";这句则是一定执行的所以千万要记得if else for while do后边接多个语句时要加大括号,原因可以看作用域这部分。所以上边代码的正确写法应该是:int a; cin >> a; if (a == 10) { a = 5; cout << "a = 10\n"; } else { cout << "a != 10\n"; } // 养成良好习惯,一句也加大括号有的人可能认为else if也是关键字什么的,其实不是,else if就是else语句后接了个if语句,本质上为if (condition) { blabla... } else { if () { blabla... } }for的使用形式为for(刚进入循环时执行一次的语句; 循环执行条件,为true才可以继续执行; 一次循环结束后执行的语句),没什么好讲的,直接上代码!int a[100]; for (int i = 0; i < 100; i++) { cin >> a[i]; } for (int i = 0; i < 100; i++) { cout << a[i]; }上边的代码做了什么事呢?首先是申明了一个大小为100的数组,之后在循环开始时申明了一个变量 i 并初始化为0,再判断i < 100为true,之后开始执行循环也就是cin >> a[i],循环体内所有语句执行完毕,自动执行i++,让i = 1...while的用法很简单,只有一个判断条件while(条件),条件为真则继续执行,使用while实现与上边for相同功能的写法是这样的:int a[100]; { int i = 0; while (i < 100) { cin >> a[i]; i++; } } { int i = 0; while (i < 100) { cout << a[i]; i++; } }为什么用了大括号呢,还是跟作用域有关,总之,while只有在条件为true时才继续执行,且不能像for一样在开始执行一次第一个‘;’前的语句dowhile和while类似,不同的是dowhile保证循环体代码至少执行一次,它是执行之后才判断条件真假,while和for则是一开始就判断do { cout << "13 * 4"; } while(false); // 记得不能忘了这个分号尽管上边的语句条件为false,但是仍然会输出“13 * 4”,这就是do while的特别之处continue break有的时候我们在循环体中可能想达到某些条件就提前退出或者不继续执行下边的代码,这时候就要用到continue、break控制了,continue的作用是跳过下边的代码,执行到循环尾也就是while (true) { a; continue; d; b; } <-这个地方 // 这是个死循环之后开始下一次循环,break是直接退出循环while (true) { a; break; d; b; } // 退出循环,不是死循环执行a之后就不会执行db了。那么实战中一般会怎么使用呢?,比如从0到100,输出所有奇数int a = 0; while (true) { if (a > 100) { break; } if (a % 1 == 0) { continue; } cout << a << ' '; }上边的例子即使用了break也使用了continue,你可以一步一步调试看看代码执行时发生了什么switch的功能有点鸡肋,你必须穷举所有结果,一般switch都跟break一起用,这就是为什么我在这才写switch,switch后边跟条件,但是与if不同,它不是判断真假,而是将条件进行匹配,这用到了另一个关键字caseint a; cin >> a; switch (a) { case 12: case 14: cout << "wow!\n"; break; default : cout << "emm..\n"; }上边的代码在输入12或者14时候会输出wow,其他情况都是emm..,这个例子同样表明不是所有case后都得跟break,如果不跟的话就会继续延顺下去,也就是说下边这种情况输入12时会输出good haha,输入14就是hahaint a; cin >> a; switch (a) { case 12: cout << "good " case 14: cout << "haha\n"; break; default : cout << "emm..\n"; }指针终于到了指针了,首先我要说明:指针一点也不难!指针也只是一个变量,它的标志就是类型中带有一个 * 号,比如int*就是int类型的指针,它可以指向一块类型为int的变量的内存,记住指针保存的就是地址就行了,这里不能理解的话那么我们抽象一下你是一个人,你叫做A,用代码表示就是人 A,你在这个地球上,你的位置(地址)是唯一的,因为不可能有人跟你重合,我们可以通过&得到你当前的位置比如经度117.42 纬度19.24 海拔345米,我们可以用一个叫人* pos = &A;来保存这个数据,同理,在程序运行时,每个变量也会有一个唯一的地址,这里不展开讨论,有兴趣的话自行了解,这个地址根据系统不同得到的结果也不同,64位系统就是64位数字32位系统就是32位数字,这个地址一定是整数,且是不会变的,我们可以通过这个地址找到这个变量的位置读取它或者修改它。int a{}; // a = 0 int *b = &a; // b = a 的地址 *b = 5; // a = 5,通过解引用修改b指向的那块地址的数据(a)的值 int c = *b; // c = 5,通过解引用读取b指向的a的值记住指针是一个变量,它保存的值是其他变量的地址,通过解引用就可以访问指针指向的变量。(*b)此刻就是a还有一点是数组与指针之间的关系,很多人都会搞错,先给出结论:数组和指针是完全不同的两个东西,唯一的关系就是数组可以退化成指针。int arr[100]; int* p = arr; // 也就是说,这句的意思不是数组和指针一样所以可以给p赋值arr,而是arr在这里退化成了指针,arr的地址储存在了p中 // 最简单的证明方法就是你不能给一个数组赋值指针,下边这句是不允许的 int* p2; int arr2[100] = p2;一个完整的数组包含了长度信息,而指针是不会包含这部分信息的。不过值得一提的是你可以对指针进行中括号运算。int arr[100]; int* p = arr; p[n] == arr[n] // 这个式子是恒成立的中括号运算本质上是通过指针 + 偏移计算元素位置,就是 p[n] 和 *(p + n)是等价的,所以你可以写出这样的代码0["ABC"]得到的结果是A。最后一小点,c++中的空指针默认为nullptr而不是NULLnullptr就是最开始提到的std::nullptr类型的数据,在写c++代码时,如果你要表示空指针,请用nullptr而不是NULL或者0。函数函数的作用是增加代码复用,因为有的句子你可能会重复写很多次,假如有的功能要几百行几千行,你又需要多次使用该功能,总不能一遍又一遍写吧,哪怕复制粘贴也是需要改一些参数的,还是很麻烦,所以这时候就可以通过函数包装一下。一个完整的函数需要 返回值类型 函数名 (函数参数) { 执行代码; 返回值;(返回类型为void时不需要返回值,但是可以通过return提前结束函数执行)}举个简单的例子int add(int a, int b) { return a + b; } int main() { std::cout << add(3, 4); // 输出7 }C++的函数可以通过修改参数进行重载,以下是一些例子(1) int a() { ... return ...; } // 先声明函数a (2) double a() { } // 错误,修改返回值类型不能重载函数 (3) int a(int x) { ... } // 没问题,这个函数a比(1)多了一个int参数 (4) double a(double x) { ... } // 没问题,(4)和(3)的参数类型不同 (5) double a(int x) { ... } // 错误,参数类型和(3)冲突 (6) int a(int x, double y) { ... } // 没问题 (7) int a(double x, int y) { ... } // 没问题,和(6)不冲突,参数虽然数量一样,但是对应参数类型不同重载函数之后在执行函数时程序会选择最匹配的函数执行(1) int a(int x) { ... } int main() { a(3.14) // 可以执行a函数,但是3.14会被转为整型也就是 3 } ------------------------------------------------------ (2) int a(int x) { ... return 1; } int a(double x) { ... return 2; } int main() { a(3.14); // 返回2 a(3); // 返回1 }函数的参数是复制进去的,所以如果你需要修改一些数据,是不能通过直接传参完成的void fun(int a) { a = 10; } int main() { int b = 89; fun(b); /** b这时候还是89,不会在fun中被修改为10 这是因为在调用fun函数时,我们执行的操作是将b赋值给a,这时候a就是一个和b完全无关的变量 对a执行任何操作都与b无关 **/ }想要修改b为10,我们有两种做法,第一种做法是通过指针来修改,如我前文所说,通过指针可以找到变量本身,这样我们修改的就是我们想要的变量,而不是一个通过复制得到的变量。void fun(int* a) { *a = 10; } int main() { int b = 89; fun(&b); // ok, 现在b = 10 }开始讲第二种方法前,我们再引入一个新的概念引用,引用说简单点就是变量的别名,小花有一个别名叫张三,有的人喜欢叫小花,有的人喜欢叫张三,虽然名字不一样,但是表示的还是同一个人,引用就是这样的,你可以通过给一个变量起别名来访问该变量。引用的声明方式是在类型后加一个&(&作用真多...)int a; int &b = a; // b是a的别名 int &c = a; // c、b都是a的别名 int &d; // 错误,引用在申明时就得初始化!!! b = 10; // a,b,c都等于10引用作为函数参数时,可以直接修改原数据void fun(int &a) { a = 10; } int main() { int a; fun(a); // a = 10 }作用域与生命周期这一部分我觉得是非常简单的,总结起来就一句话一对大括号内的内容属于一个作用域,变量的生命周期从申明开始到离开大括号结束,全局变量、静态变量生命周期贯穿整个程序。举例子:1. void f() { 2. int a; 3. int b; 4. { 5. int c; 6. std::cin >> c; 7. } 8. std::cin >> c; 9. int c; 10. }想想上边的代码有问题吗?如果有那是第几行?这个函数中我们声明了两次变量c,错误点在这吗?当然不是。我们把1-10行叫作用域1,4-7行叫作用域2,我们先在作用域2声明了c并使用cin输入c。在离开作用域2之后又再一次尝试输入变量c,这时候就有问题了,离开了作用域2,变量c的生命周期结束,这时候在cin时不可以的,因为不知道c是啥,所以错误点在第8行。变量ab的生命周期一直到函数执行完毕。你可以自己写一些例子实验一下,亲自体会一下生命周期、作用域。 -
[C++QUIZ]#251 #243 251#include <iostream> template<class T> void f(T) { std::cout << 1; } template<> void f<>(int*) { std::cout << 2; } template<class T> void f(T*) { std::cout << 3; } int main() { int *p = nullptr; f( p ); }{card-describe title="输出"}3{/card-describe}{callout color="#f0ad4e"}这道题没有那么简单的, 也让我更了解模板首先在模板解析时不考虑特化版本, 所以这里有两个重载void f(T)和void f(T*), 很简单的我们的p匹配的应该是void f(T*)这是毋庸置疑的, 因为第二个比第一个更能描述参数特征那么按理说特化版本的void f<>(int*)才是最匹配的, 这里为什么不输出2呢?这里需要搞清楚一件事void f<>(int*)是哪个模板的特化标准中提到了A declaration of a function template (...) being explicitly specialized shall precede the declaration of the explicit specialization.说明我们应该先有模板再有特化, void f<>(int*)是在void f(T*)之前的. 所以void f<>(int*)是void f(T)的特化, 在第一次的选择中void f(T)已经被淘汰, 故也不选择它的特化版本void f<>(int*), 所以输出3{/callout}243#include <iostream> template <typename T> struct A { static_assert(T::value); }; struct B { static constexpr bool value = false; }; int main() { A<B>* a; std::cout << 1; } {card-describe title="输出"}1{/card-describe}{callout color="#f0ad4e"}第一眼static_assert(false)秒了, 然后错误在这个例子中, A<B>如果被实例化, 那么显然是不能编译通过的, 在程序中并没有出现显式特化或者显式实例化, 那么接下来考虑的就是有没有出现隐式实例化这里的A<B>仅仅是指针而不需要对应类型的对象, 所以也没有被隐式实例化, 故可以输出1你可以看到有没有A<B>* a这行生成的汇编都一样{/callout}
-
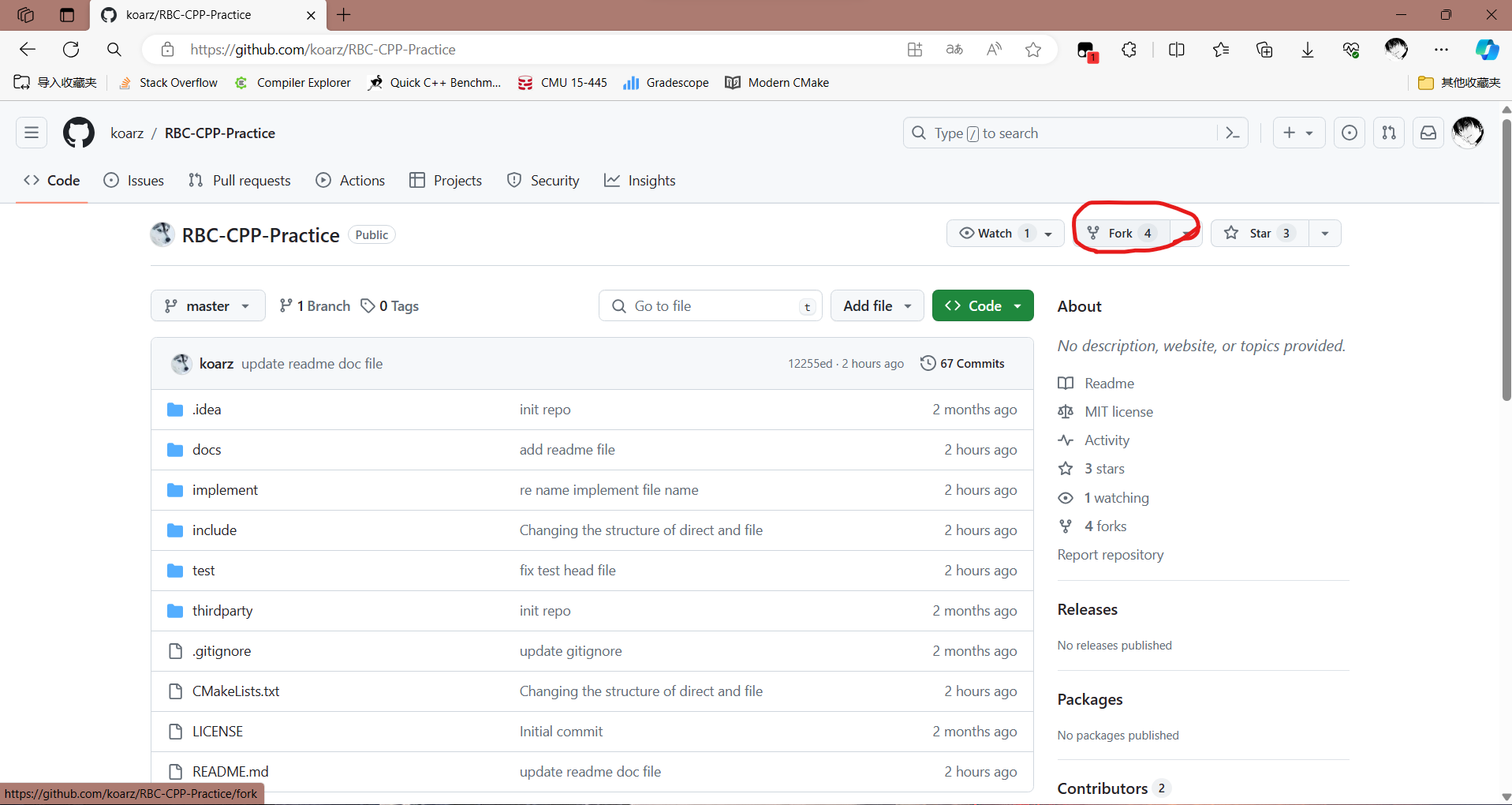
How to start RBC CPP Practice Github首先你需要注册一个github账号,再打开仓库链接,点击这里fork仓库。在这里点击Create fork接着回到github主界面,打开你刚才fork的仓库,像这里这样点绿色的Code复制链接这时候你需要一个linux环境,如果你有linux主机,那太好了,接下来这一步可以跳过,如果你没有linux环境那么可以安装VMWare,或者wsl,这里我用的是wsl,所以接下来我讲一下如何安装使用wsl,以及如何用你的VSCode连接上你的wsl(VM教程很多,随便都能找到,我电脑没VM所以这里不讲了)wsl打开你的powershell,输入下边的命令:wsl --install下载时候你会看到这样的界面下载成功后需要你配置用户名密码,自己记好,用户名别用中文。如果没有这步,先重启再继续输入上边的命令。下载成功后重启电脑,这样就下载好Ubuntu环境了,我们进入下一步,配置VSCode。默认的wsl是下载到C盘的,如果你不想放在C盘,那么可以看这个文章WSL的安装和位置迁移VSCode这里主要讲仓库的拉取,具体VSCode调试配置请看这篇文章VSCode配置大法首先打开你的VSC,在插件这里搜索remote,下载remote-ssh之后点击VSC的左下角><这个按钮你可以看到这个界面选择WSL,打开以后你进成功进入到wsl里的ubuntu虚拟机了,然后在终端下载你的代码库像这样可以看到RBC-CPP-Practice已经被拉取下来了,接着点击VSC左上角的文件>打开文件夹选择你RBC-CPP-Practice文件夹并确认这样所有准备工作都做完了,开始学习吧!运行test在进入到项目文件夹之后,输入一次mkdir build cd build cmake ..之后 Ctrl+Shift+p 搜索 reload window选择确认等你写完对应hpp想要测试自己实现的是否正确时就按照下图输入命令,这里以list_test为例可以看到有一些黄色的和绿色的,黄色的就是不需要你必须完成的,绿色的就是测试通过的,如果出现红色的,那么说明你的实现有问题。再改改吧。如果你想运行完整测试,那么就像这样,删除这里的DISABLED_再make一下test重新测试,全绿的话恭喜你,你通过了所有测试!你可以选择提交你的实现,注意提交时候不要修改到原本仓库的文件,仅提交你自己的实现,你的实现将会成为其他人的参考,如果你愿意最好加上足够详细的注释,方便其他人阅读注意你的WSL可能不能通过https链接拉取仓库代码,这时候你就需要通过ssh拉取了具体是在终端输入ssh-keygen -t rsa,然后一路回车,再cat ./.ssh/id_rsa.pub你会看到一串以 ssh-rsa 开头长得像乱码的东西,复制这一串东西打开 https://github.com/settings/keys点New SSH key,title随便起,把你复制的内容输入到下边的Key的大框里提交即可,然后在你fork的仓库界面选择ssh链接也就是第三张图的https旁边的那里的链接,其他步骤一样提交你的实现时一定要保证全绿通过才行
-
[C++]通过智能指针的实现理解RAII C以及C++的内存管理是让人很头疼的,指针满天飞,或者是忘了及时释放内存导致内存泄漏,多线程情况下加了锁忘记unlock...一些其他语言例如java有gc来防止内存泄漏,C++也有类似机制,那就是RAII:资源获取即初始化(Resource Acquisition Is Initialization)关于RAII的具体介绍可以看cppreference,简单来讲就是将需要管理的资源与对象的生命周期绑定,当对象析构时可以自动(通过析构函数)释放所管理的资源。RAII应用的典型就是智能指针了,接下来我会讲讲智能指针的实现以及原理,让你理解这一工具(可以叫工具吗?我不知道){dotted startColor="#ff6c6c" endColor="#1989fa"/}首先讲讲程序运行时的堆栈结构吧我们熟知的main函数以及其他各种函数都是在栈上运行的,具体结构类似这样: 在栈上储存着普通的变量,或者对象什么的,图中的情况就是类似这样一段代码运行时的情况void fun2() { int a{}; SomeClass b; ... } void fun1() { ... fun2(); ... } int main() { ... fun1(); ... }如果fun2执行完毕,那么图中fun1以下的地方都会被“移除”,也就是出栈了,接着继续执行fun1中的剩余代码。 于是我们可以知道,fun2内部的所有变量(a,b...)的生命周期都随着fun2执行结束而结束了,那么如果b就是一个std::unique_ptr,这时候b所管理的资源也就随着b的析构而被释放了。如果你没看懂的话我们可以将这个例子写得更具体一点。#include <iostream> using namespace std; class A { public: A() { cout << "A()\n"; } ~A() { cout << "~A()\n"; } }; void fun2() { cout << "fun2 begin\n"; A b; cout << "fun2 end\n"; } void fun1() { cout << "fun1 begin\n"; fun2(); cout << "fun1 end\n"; } int main() { cout << "main begin\n"; fun1(); cout << "main end\n"; return 0; }{card-default label="运行结果" width=""}main beginfun1 beginfun2 beginA()fun2 end~A()fun1 endmain end{/card-default}这样对象的生命周期是不是就很直观了,我们就可以理解std::unique_ptr在执行过程中做了什么。这里给出一个简单的unique_ptr的实现:#pragma once namespace koarz { template <typename T> class unique_ptr; } // namespace koarz template <typename T> class koarz::unique_ptr { private: T *ptr_; public: unique_ptr() : ptr_(nullptr){}; unique_ptr(T *ptr) : ptr_(ptr){}; unique_ptr(koarz::unique_ptr<T> &) = delete; unique_ptr &operator=(koarz::unique_ptr<T> &) = delete; unique_ptr(koarz::unique_ptr<T> &&) noexcept; unique_ptr &operator=(koarz::unique_ptr<T> &&) noexcept; T *operator->() const { return ptr_; } T &operator*() const { return *ptr_; } T *get() const { return ptr_; } T *release() { T *tmp = ptr_; ptr_ = nullptr; return tmp; } void reset(T *ptr = nullptr) { if (ptr_ != ptr) { delete ptr_; } ptr_ = ptr; } ~unique_ptr() { delete ptr_; } }; template <typename T> koarz::unique_ptr<T>::unique_ptr(koarz::unique_ptr<T> &&other) noexcept { ptr_ = other.ptr_; other.ptr_ = nullptr; } template <typename T> koarz::unique_ptr<T> & koarz::unique_ptr<T>::operator=(koarz::unique_ptr<T> &&other) noexcept { if (ptr_ != other.ptr_) { delete ptr_; } ptr_ = other.ptr_; other.ptr_ = nullptr; return *this; } 可以看到在析构函数中呢,我们对unique_ptr管理的内存进行了释放,也就是在执行上边代码的~A的时候释放了这块内存,fun2就可以改成这样:void fun2() { koarz::unqiue_ptr<int> a(new int(10)); cout << *a << endl; } // 我并没有实现make_unique所以我这里直接new了,但是一般使用智能指针我们会使用 // unique_ptr<int> a = make_unique<int>(10);智能指针的资源不应该在构造期间构造这段代码肯定会输出10然后析构掉new出来的内存,这就是智能指针管理内存的方式也就是利用RAII技术完成资源管理的一个例子。RAII的应用有很多std::unique_ptr 及 std::shared_ptr 用于管理动态分配的内存,或以用户提供的删除器管理任何以普通指针表示的资源;std::lock_guard、std::unique_lock、std::shared_lock 用于管理互斥体。最后再贴上shared_ptr的简单实现,你可以试着理解shared_ptr与unique_ptr的不同在哪。#pragma once #include <atomic> namespace koarz { template <typename T> class shared_ptr; } // namespace koarz template <typename T> class koarz::shared_ptr { private: T *ptr_{nullptr}; std::atomic_uint *count_{nullptr}; void release() { if (count_ != nullptr) { (*count_)--; if (*count_ == 0) { delete count_; delete ptr_; count_ = nullptr; ptr_ = nullptr; } } } public: shared_ptr() : ptr_(nullptr), count_(nullptr){}; shared_ptr(T *ptr) : ptr_(ptr) { count_ = new std::atomic_uint(1); }; shared_ptr(const koarz::shared_ptr<T> &) noexcept; shared_ptr &operator=(const koarz::shared_ptr<T> &) noexcept; shared_ptr(koarz::shared_ptr<T> &&) noexcept; shared_ptr &operator=(koarz::shared_ptr<T> &&) noexcept; T *operator->() const { return ptr_; } T &operator*() const { return *ptr_; } T *get() const { return ptr_; } void reset(T *ptr = nullptr) { if (ptr == ptr_ || ptr == nullptr) return; ptr_ = ptr; if (count_ != nullptr) { *count_ = 1; } else { count_ = new std::atomic_uint(1); } } void swap(koarz::shared_ptr<T> &); int get_count() { return *count_; } ~shared_ptr(); }; template <typename T> koarz::shared_ptr<T>::shared_ptr(const koarz::shared_ptr<T> &other) noexcept { if (other.ptr_ != this->ptr_) { release(); ptr_ = other.ptr_; count_ = other.count_; (*count_)++; } } template <typename T> koarz::shared_ptr<T> & koarz::shared_ptr<T>::operator=(const koarz::shared_ptr<T> &other) noexcept { if (other.ptr_ != this->ptr_) { release(); ptr_ = other.ptr_; count_ = other.count_; (*count_)++; } return *this; } template <typename T> koarz::shared_ptr<T>::shared_ptr(koarz::shared_ptr<T> &&other) noexcept { if (other.ptr_ != this->ptr_) { release(); ptr_ = other.ptr_; count_ = other.count_; } } template <typename T> koarz::shared_ptr<T> & koarz::shared_ptr<T>::operator=(koarz::shared_ptr<T> &&other) noexcept { if (other.ptr_ != this->ptr_) { release(); ptr_ = other.ptr_; count_ = other.count_; } return *this; } template <typename T> koarz::shared_ptr<T>::~shared_ptr() { if (count_ != nullptr) { (*count_)--; if (*count_ == 0) { delete ptr_; delete count_; } } } // 这段代码当然没有完整实现,你可以试着让它更加完善shared_ptr只有在引用计数为0的情况下才会delete掉管理的内存,而拷贝时会增加引用计数,一般情况下shared_ptr对象析构时只会减少引用计数,这样就保证了最后一个共享这块内存的对象析构时才会释放这块内存。
-
[C++]换个方式理解移动构造和拷贝构造 相信大部分初学者(当然包括我)都会对移动构造和拷贝构造有不理解的地方,或者理解有一定的误区,虽然很多人都在讲这个东西,但是自己本来就没懂,所以听着也是稀里糊涂没听明白,但是没关系,我会用最通俗易懂的例子让你理解它。首先看看这个例子:class Widget { public: Widget(); Widget(Widget &); Widget(Widget &&); private: Datatype *data; }这就是一个基本的拥有三种构造函数的类,当我们用不同的方式初始化一个该类的对象的时候,他就会根据对应的参数调用对应的构造函数,注意我说的对应!这是理解它们区别的很重要的点。接下来步入正题,让我们转换视角。把你自己抽象成data现在你就是这个Widget里的data,Widget就是承载你的物体的类,具体可能是大地或者是床,甚至是火星,或者......总之你就处在Widget上对人来说,当我们从地上上了床,这个过程对应了哪个构造函数呢?当然是一都构造了,对应代码就是:Widget floor; // floor 里的data就是现在的你,代表你现在在地上 // 现在你想上床躺会 Widget bed(std::move(floor)); // 现在把你移动到床上你从地面上移动到床上的过程就被抽象成了这样,还可以理解对吧。哦,我好像忘了定义 Widget(Widget &&) ,现在来定义它。Widget(Widget &&other) { data = other.data; // 将other.data复制给data就是你从地上到了床上 other.data = nullptr; // 将other.data置空的原因是你现在已经不在地上了 }结合注释,还是很好理解对吧。那么继续。如果是拷贝构造?现在你还是data,试想一下如果在这个过程是拷贝的呢?床上一个你,地下一个你,为了让床上有一个你,我们需要先造一个你的克隆体,因为不会凭空再出现一个你对吧,那么这个制造克隆体的开销就是拷贝构造相对移动构造的开销,当然这只是一部分。想想你为什么想上床呢?因为你不想再待在地上了对吧,所以你根本不需要大费周章克隆一个你,你自己上去不就行了吗?那什么时候需要拷贝构造呢?我们事一多的时候,不都经常想再多几个我就好了,因为这些事情都需要你,所以多几个你明显效率更高。左值右值只是为了区分那么再想我们一些情况下是要克隆一个自己,还是自己直接过去就好了,我们要对这两种情况做个区分,我们可以打标签对吧,对C++来说这个标签就是看它是左值还是右值,右值代表需要移动,左值代表需要克隆,就这样。再看我开头说的对应,可以理解了吗?就是编译器根据这个标签选择是调用拷贝构造还是移动构造。std::move();做的就是给Widget对象打上标签,代表需要移动。我不需要待在原地,那么我就移动,我就是右值,我需要一个克隆体,那么我就是左值。希望对你有帮助,如果有错误,欢迎纠正。
![[C++QUIZ]#251 #243](https://a.koarz.top/usr/uploads/2024/07/3247274755.png)
![[C++]通过智能指针的实现理解RAII](https://picst.sunbangyan.cn/2024/01/11/7db2aab28658ba7966779ffca7e1fb84.jpeg)
![[C++]换个方式理解移动构造和拷贝构造](http://www.koarz.top/usr/themes/Joe/assets/thumb/12.jpg)