


搜索到
24
篇与
的结果
-
![[doris]doris笔记](https://npm.elemecdn.com/typecho-joe-latest/assets/img/lazyload.jpg) [doris]doris笔记 Image + CheckpointCheckpoint 相关代码在fe/fe-core/src/main/java/org/apache/doris/master/Checkpoint.java中,主要部分为 doCheckpoint() 函数该函数主要逻辑为:检查 imageVersion 和 checkPointVersion 的大小关系, 如果 image版本 比 checkpoint版本新那么直接返回(说明checkpoint过时了不需要做同步)检查内存是否足够去做 checkpoint写 image 文件,做持久化,将 image.ckpt 移动到 image.dataVersion 文件加载 image 文件,检查 image 是否有效,至此 image 文件保存完毕将 image 文件发送给所有非 master fe 节点当 5 完成之后删除它们的旧版本日志删除 master 的旧版本日志image文件格式:|- Image --------------------------------------| | - Magic String (4 bytes) | | - Header Length (4 bytes) | | |- Header -----------------------------| | | | |- Json Header ---------------| | | | | | - version | | | | | | - other key/value(undecided)| | | | | |-----------------------------| | | | |--------------------------------------| | | | | |- Image Body -------------------------| | | | Object a | | | | Object b | | | | ... | | | |--------------------------------------| | | | | |- Footer -----------------------------| | | | - Checksum (8 bytes) | | | | |- object index --------------| | | | | | - index a | | | | | | - index b | | | | | | ... | | | | | |-----------------------------| | | | | - other value(undecided) | | | |--------------------------------------| | | - Footer Length (8 bytes) | | - Magic String (4 bytes) | |----------------------------------------------|相关代码在:fe/fe-core/src/main/java/org/apache/doris/persist/meta/MetaReader.java
[doris]doris笔记 Image + CheckpointCheckpoint 相关代码在fe/fe-core/src/main/java/org/apache/doris/master/Checkpoint.java中,主要部分为 doCheckpoint() 函数该函数主要逻辑为:检查 imageVersion 和 checkPointVersion 的大小关系, 如果 image版本 比 checkpoint版本新那么直接返回(说明checkpoint过时了不需要做同步)检查内存是否足够去做 checkpoint写 image 文件,做持久化,将 image.ckpt 移动到 image.dataVersion 文件加载 image 文件,检查 image 是否有效,至此 image 文件保存完毕将 image 文件发送给所有非 master fe 节点当 5 完成之后删除它们的旧版本日志删除 master 的旧版本日志image文件格式:|- Image --------------------------------------| | - Magic String (4 bytes) | | - Header Length (4 bytes) | | |- Header -----------------------------| | | | |- Json Header ---------------| | | | | | - version | | | | | | - other key/value(undecided)| | | | | |-----------------------------| | | | |--------------------------------------| | | | | |- Image Body -------------------------| | | | Object a | | | | Object b | | | | ... | | | |--------------------------------------| | | | | |- Footer -----------------------------| | | | - Checksum (8 bytes) | | | | |- object index --------------| | | | | | - index a | | | | | | - index b | | | | | | ... | | | | | |-----------------------------| | | | | - other value(undecided) | | | |--------------------------------------| | | - Footer Length (8 bytes) | | - Magic String (4 bytes) | |----------------------------------------------|相关代码在:fe/fe-core/src/main/java/org/apache/doris/persist/meta/MetaReader.java -
[论文]The Log-Structured Merge-Tree (LSM-Tree)翻译 摘要.高性能的事务系统应用程序通常会在历史表中插入行,以提供活动的跟踪;同时,事务系统生成日志记录以用于系统恢复。这两种生成的信息都可以从高效的索引中受益。一个著名的例子是TPC-A基准应用程序,它被修改以支持对特定账户的历史活动的高效查询。这要求在快速增长的历史表上按账户ID建立索引。不幸的是,标准的基于磁盘的索引结构(例如B树)会有效地将事务的I/O成本加倍,以实时维护这样的索引,从而使系统总成本增加高达50%。显然,找到一种低成本的实时索引维护方法是非常有价值的。Log-Structured Merge-tree (LSM树) 是一种基于磁盘的数据结构,设计用于为高频插入(和删除)记录的文件提供低成本的索引。LSM树使用一种算法,将索引更改推迟并批量处理,以类似归并排序的高效方式将更改从基于内存的组件级联至一个或多个磁盘组件。在此过程中,所有索引值始终可以进行检索(除了非常短暂的锁定期间),可以通过内存组件或磁盘组件之一进行访问。与传统的访问方法(如B树)相比,该算法大大减少了磁盘臂的移动,从而在插入操作的磁盘臂成本高于存储介质成本的领域中提高了成本性能。LSM树方法也可以推广到除插入和删除以外的操作。然而,在某些情况下,需要立即响应的索引查找操作将会失去I/O效率,因此LSM树在插入操作比检索条目更常见的应用中最为有用。例如,这似乎是历史表和日志文件的常见特性。第6节的结论将LSM树访问方法中内存和磁盘组件的混合使用与常见的混合方法优势进行了比较,即将磁盘页缓冲在内存中的优势。引言随着活动流管理系统中的长期事务逐渐商用化([10], [11], [12], [20], [24], [27]),对事务日志记录的索引访问需求也将不断增加。传统的事务日志记录主要关注事务的中止和恢复,通常只需系统在正常处理过程中参考相对短期的历史,并在偶尔的事务回滚时使用批量顺序读取进行恢复。然而,随着系统承担更复杂的活动,组成单个长期活动的事件持续时间和数量将增加,甚至有时需要实时查看过去的事务步骤,以提醒用户已完成的内容。同时,系统已知的活跃事件总数将增加,以至于目前用于跟踪活跃日志的内存常驻数据结构变得不可行,尽管预计内存成本将继续降低。对大量过去活动日志的查询需求意味着索引日志访问将变得越来越重要。即使在当前的事务系统中,为支持高插入量的历史表查询提供索引也是很有价值的。网络系统、电子邮件以及其他准事务系统往往生成大量日志,给其宿主系统带来负担。为了从具体且广为人知的示例开始,我们在接下来的示例1.1和1.2中探讨了修改后的TPC-A基准。请注意,本文中呈现的示例涉及特定的数值参数以便于演示;推广这些结果是很简单的。另外,虽然历史表和日志都涉及时间序列数据,但LSM树的索引项并不假设具有相同的时间键顺序。提高效率的唯一假设是更新速率高于检索速率。五分钟法则以下两个示例都依赖于“五分钟法则” [13]。这一基本结果表明,当页面引用频率超过每60秒一次时,通过购买内存缓冲区来保持页面在内存中,从而避免磁盘I/O,可以降低系统成本。60秒的时间段是一个近似值,它反映了磁盘臂提供每秒一个I/O的折算成本与4 KB磁盘页面的内存缓冲成本之间的比率。按照第3节的符号表示,这个比率是COSTP/COSTm除以页面大小(以MB为单位)。这里我们只是利用磁盘访问与内存缓冲之间的权衡获得经济上的收益。请注意,随着内存价格下降得比磁盘臂更快,这一60秒的时间段预计会随着时间的推移而增加。1995年时这一时间段比1987年定义的五分钟更短,部分原因是技术因素(不同的缓冲假设),部分原因是极其廉价的大量生产磁盘的引入。示例1.1考虑TPC-A基准所设想的多用户应用程序[26],其每秒运行1000个事务(此速率可以调整,但以下我们仅考虑1000 TPS)。每个事务在三个表中的一行中随机选取一个包含100字节的行,对其Balance列值进行更新,减去一个Delta金额:Branch表包含1000行,Teller表包含10,000行,而Account表包含100,000,000行;事务然后在提交前向History表写入一行50字节的数据,其中包含列:Account-ID, Branch-ID, Teller-ID, Delta和Timestamp。计算表明,Account表的页面在未来几年内不会常驻内存(见参考文献[6]),而Branch和Teller表应该可以完全驻留在内存中。在给定的假设下,对Account表的同一磁盘页面的重复访问间隔大约为2500秒,远低于根据五分钟法则维持缓冲驻留所需的频率。现在每个事务需要大约两个磁盘I/O,一个用于读取所需的Account记录(我们将访问到缓冲中的页面的情况视为微不足道),另一个用于将之前的脏Account页面写出,以在缓冲区中腾出空间以供读取(这是稳态操作所必需的)。因此,1000 TPS对应于大约2000次I/O每秒。这在假定每磁盘臂每秒25次I/O的名义速率下需要80个磁盘臂(参见[13])。从1987年到1995年,速率每年增长不到10%,使得名义速率现在大约为每秒40次I/O,即2000 I/O每秒需要50个磁盘臂。根据参考文献[6],磁盘的成本约占TPC应用系统总成本的一半,尽管在IBM大型机系统上的成本有所减少。然而,随着内存和CPU成本下降速度快于磁盘,支持I/O的成本显然已成为系统总成本的一个日益增长的组成部分。示例1.2现在我们考虑一个高插入量的History表索引,并展示该索引如何实质上将TPC应用程序的磁盘成本翻倍。对于History表上的“Account-ID和Timestamp拼接”(Acct-ID||Timestamp)的索引,对于支持最近账户活动的高效查询至关重要,如以下查询:(1.1)Select * from History where History.Acct-ID = %custacctid and History.Timestamp > %custdatetime; 如果缺少Acct-ID||Timestamp索引,则这样的查询需要直接搜索History表的所有行,因此实际上不可行。仅在Acct-ID上创建索引可以提供大部分的优势,但如果不包含Timestamp,成本考虑不会改变,因此我们在此假设更有用的拼接索引。维护此类实时的B树索引需要哪些资源?我们看到每秒生成1000条B树项,并假设一个20天的累计周期,每天8小时,索引项大小为16字节,这意味着磁盘上有576,000,000个条目,占用约9.2 GB的空间,即在索引叶级上大约需要2.3百万个页面,即使没有浪费空间。由于事务性Acct-ID值是随机选择的,每个事务至少需要一次从该索引中读取页面,并在稳态下还需写出页面。根据五分钟法则,这些索引页面不会驻留在缓冲区中(磁盘页面读取间隔约2300秒),因此所有I/O均为磁盘操作。这种新增的2000次每秒I/O,加上更新Account表所需的2000次每秒I/O,需要额外购买50个磁盘臂,磁盘需求翻倍。上述数值乐观地假设可以在非高峰时段批量执行删除操作,以将日志文件索引保持在20天的长度之内。我们为History文件中的Acct-ID||Timestamp索引选择了B树,因为它是商业系统中最常用的基于磁盘的访问方法,事实上,没有传统的磁盘索引结构能够始终提供更优的I/O成本/性能。我们将在第5节中讨论得出此结论的原因。本文提出的LSM树访问方法使我们能够以更少的磁盘臂使用成本,执行Account-ID||Timestamp索引的频繁插入操作,因此成本降低一个数量级。LSM树采用一种推迟和批量处理索引更改的算法,以类似归并排序的高效方式将更改迁移到磁盘上。正如我们将在第5节看到的那样,将索引项位置推迟到最终磁盘位置的功能至关重要,而在一般的LSM树情况下,还存在一系列级联的推迟位置。LSM树结构还支持索引的其他操作,例如删除、更新,甚至长延迟查找操作,具有相同的推迟效率。只有需要立即响应的查找操作的成本相对较高。LSM树的一个重要应用领域如示例1.2所示,在插入操作远比检索操作频繁的情况下(例如,大多数人查询最近账户活动的频率远低于支票存款的频率)。在这种情况下,降低索引插入成本至关重要;同时,查找访问的频率足够高,以至于必须维护某种类型的索引,因为遍历所有记录的顺序搜索是不可行的。本文的结构如下。在第2节中,我们介绍了双组件的LSM树算法。在第3节中,我们分析了LSM树的性能,并探讨多组件LSM树的动机。在第4节中,我们简要介绍了LSM树的并发性和恢复概念。第5节中,我们考察了在感兴趣的应用中,其他竞争性访问方法的性能。第6节包含结论,评估了LSM树的一些影响,并提供了一些扩展建议。2 双组件LSM树算法LSM树由两个或多个树状的组件数据结构组成。本节我们讨论简单的双组件情况,并假设LSM树用于索引示例1.2中History表中的行。参见下方的图2.1。一个双组件LSM树有一个较小的组件,完全驻留在内存中,称为C0树(或C0组件),以及一个驻留在磁盘上的较大组件,称为C1树(或C1组件)。尽管C1组件驻留在磁盘上,但C1中经常被引用的页面节点会如常保留在内存缓冲区中(缓冲区未显示),因此可以保证C1的高层目录节点驻留在内存中。当生成每条新的History行时,首先将用于恢复该插入的日志记录以常规方式写入顺序日志文件。接着,History行的索引条目插入内存驻留的C0树中,之后它会逐步迁移到磁盘上的C1树中;任何索引条目的搜索会先在C0树中查找,然后再在C1树中查找。在C0树中的条目迁移到磁盘驻留的C1树之前存在一定的延迟(延迟),这意味着需要恢复那些在崩溃前未写入磁盘的索引条目。恢复过程将在第4节中讨论,目前我们仅指出,可以将允许我们恢复History行新插入内容的日志记录视为逻辑日志;在恢复期间,我们可以重建已插入的History行,同时重建必要的索引条目,以重新获得丢失的C0内容。将索引条目插入内存驻留的C0树没有I/O成本。然而,与磁盘相比,容纳C0组件的内存成本较高,这限制了其大小。因此,我们需要一种高效的方法将条目迁移到驻留在低成本磁盘介质上的C1树。为此,只要C0树因插入操作达到接近最大允许的阈值大小,就会启动一个滚动合并过程,将C0树中某一连续段的条目删除,并将其合并到磁盘上的C1树中。图2.2描绘了滚动合并过程的概念图。C1树的目录结构与B树类似,但进行了优化以适应顺序磁盘访问,节点100%填满,根节点以下的每一层中的单页节点序列被打包成连续的多页磁盘块,以提高磁盘臂的效率;这种优化也在SB树中使用过【21】。在滚动合并和长距离检索过程中使用多页块I/O,而在匹配索引查找时使用单页节点,以最小化缓冲需求。设想根节点以下的多页块大小为256 KB,根节点定义上始终为单页。滚动合并以一系列合并步骤执行。C1树的叶节点被读取到一个多页块中,使得C1树中的一系列条目驻留在缓冲区中。每个合并步骤接着读取缓冲块中的一个磁盘页大小的C1树叶节点,将其条目与来自C0树叶级别的条目合并,从而减小C0的大小,并创建C1树的新合并叶节点。在合并前包含旧C1树节点的缓冲多页块称为空块,而新合并的C1树叶节点被写入另一个称为填充块的缓冲多页块中。当这个填充块已满且包含新合并的C1叶节点时,它会写入磁盘上的新空闲区域。图2.2中,新包含合并结果的多页块位于旧节点的右侧。后续的合并步骤将逐步合并C0和C1组件中增大的索引值段,直到达到最大值,滚动合并再从最小值开始。新合并的块被写入新的磁盘位置,因此旧块不会被覆盖,这样在崩溃时可以用于恢复。C1中的父目录节点也缓存在内存中,并会更新以反映新的叶节点结构,但通常会更长时间地保留在缓冲区中以减少I/O;合并步骤完成后,来自C1组件的旧叶节点会被标记为无效,并从C1目录中删除。通常,在每次合并步骤后,合并后的C1组件会剩下一些叶级别的条目,因为合并步骤不太可能恰好在旧叶节点清空时生成一个新节点。多页块也有类似情况,因为当填充块满载新合并的节点时,通常会在缩小的块中仍然保留许多包含条目的节点。这些剩余的条目以及更新的目录节点信息会暂时留在块内存缓冲区中,而不会立即写入磁盘。关于在合并步骤中提供并发性和在崩溃时恢复丢失内存的技术将在第4节详细讨论。为了减少恢复中的重建时间,合并过程会定期进行检查点操作,将所有缓冲的信息强制写入磁盘。2.1 两组件 LSM 树的增长方式为了追踪 LSM 树从开始增长到成熟的演变过程,我们先从第一次插入到内存中的 C0 树组件开始。与 C1 树不同,C0 树不必具有类似 B 树的结构。一方面,节点可以是任意大小:由于 C0 树从不存储在磁盘上,因此我们不需要坚持磁盘页面大小的节点,也不需要牺牲 CPU 效率来最小化树的深度。因此,(2-3) 树或 AVL 树(例如在 [1] 中解释的那样)都可以作为 C0 树的备选结构。当增长中的 C0 树首次达到其阈值大小时,从 C0 树中删除一个最左边的条目序列(应采用高效的批处理方式,而不是一次删除一个条目),并重新组织为 100% 填满的 C1 树叶节点。连续的叶节点从左到右放置在一个缓冲区内的多页块的初始页面中,直到该块填满;然后,这个块被写入磁盘,成为 C1 树磁盘驻留叶级的第一个部分。随着连续叶节点的添加,C1 树的目录节点结构在内存缓冲区中创建,具体细节如下所述。C1 树叶级的连续多页块按不断增加的关键字顺序写入磁盘,以防止 C0 树超过其阈值。C1 树的上层目录节点在单独的多页块缓冲区中或单页缓冲区中维护,具体选择取决于总内存和磁盘臂成本的考量;这些目录节点中的条目包含分隔符,用于将访问导向下方的单页节点,就像 B 树中的结构一样。目的是沿着单页索引节点路径提供高效的精确匹配访问,直达叶级,从而在这种情况下避免多页块读取,以最小化内存缓冲区需求。因此,我们在滚动合并或长程检索时读取和写入多页块,而在索引查找(精确匹配)访问时使用单页节点。支持这种二分方法的稍有不同的结构在 [21] 中提出。C1 目录节点的部分填满的多页块通常允许在写入一系列叶节点块的同时留在缓冲区中。当以下情况发生时,C1 目录节点会被强制写入磁盘上的新位置:一个包含目录节点的多页块缓冲区已满根节点分裂,增加了 C1 树的深度(使其深度大于两层)执行了检查点操作在第一种情况下,已填满的单个多页块会写入磁盘。在后两种情况下,所有多页块缓冲区和目录节点缓冲区都会被刷新到磁盘上。当 C0 树的最右叶节点第一次写入到 C1 树中后,进程会从两个树的左端重新开始,但现在以及之后的每一轮,C1 树的多页叶级块必须读入缓冲区,并与 C0 树中的条目合并,从而创建新的 C1 树多页叶块写入磁盘。一旦合并开始,情况会更加复杂。我们可以将两组件 LSM 树中的滚动合并过程设想为一个概念性的“游标”,该游标以量化步长缓慢地循环穿过 C0 树和 C1 树组件中具有相同键值的部分,将索引数据从 C0 树转移到磁盘上的 C1 树。滚动合并游标在 C1 树的叶级以及每一个更高的目录级别上都有一个位置。在每个级别,所有当前正在合并的 C1 树多页块通常会被分为两个块:“清空”块和“填充”块。“清空”块包含已被耗尽但仍保留未被合并游标触及的信息的条目,而“填充”块则反映了合并到目前为止的结果。类似地,每个级别都会有一个表示游标的“填充节点”和“清空节点”,这些节点肯定会常驻缓冲区。为了支持并发访问,每个级别的清空块和填充块都包含 C1 树中的整页大小节点,这些节点仅暂时驻留在缓冲区中。(在重组个别节点的合并步骤期间,对这些节点条目的其他并发访问会被阻塞。)每当需要完全刷新所有缓冲节点到磁盘时,每个级别的所有缓冲信息必须被写入磁盘上的新位置(其位置会在上级目录信息中反映,并且会有用于恢复的顺序日志条目)。稍后,当 C1 树某一级别中的填充块在缓冲区中装满并需要再次刷新时,它将被写入一个新的位置。旧的信息在恢复期间可能仍需要,因此不会直接覆盖,只是随着更新信息的成功写入而被标记为无效。在第 4 节中有更详细的滚动合并过程的解释,涵盖了并发性和恢复设计。对于 LSM 树来说,当 C1 树某一级别的滚动合并过程以相对较高的速度穿过节点时,所有读写操作都发生在多页块中,这一点在效率上尤为重要。通过消除寻道时间和旋转延迟,相比于普通 B 树中条目插入时涉及的随机页面 I/O,我们可以获得巨大的优势(此优势在第 3.2 节中进行分析)。始终将多页块写入新位置的理念受到了 Rosenblum 和 Ousterhout 提出的日志结构化文件系统(Log-Structured File System)的启发,LSM 树也因此得名。值得注意的是,为新多页块写入连续使用新磁盘空间意味着写入的磁盘区域会循环,旧的已废弃块必须被重用。这种记录可以通过内存表来完成;旧的多页块会被标记为无效并作为单元重新使用,恢复通过检查点来保证。在日志结构化文件系统中,旧块的重用会涉及大量 I/O,因为这些块通常只部分释放,因此重用需要一次块读取和块写入。而在 LSM 树中,块在滚动合并的尾部会完全释放,因此不会涉及额外的 I/O。2.2 在 LSM 树索引中查找当通过 LSM 树索引执行精确匹配查找或需要立即响应的范围查找时,首先会在 C0 树中进行搜索,然后在 C1 树中搜索所需的值或值范围。与 B 树相比,这可能会带来轻微的 CPU 开销,因为可能需要搜索两个目录。对于有多个组件的 LSM 树,还可能会产生一些 I/O 开销。为了对第 3 章有所预见,我们可以将多组件 LSM 树定义为由 C0、C1、C2、...、CK-1 和 CK 组成的索引树结构,组件尺寸依次增大,其中 C0 为内存驻留,其他所有组件都驻留在磁盘上。在所有组件对 (Ci-1, Ci) 之间存在异步滚动合并过程,每当较小的组件 Ci-1 超出其阈值时,条目会从较小组件移动到较大组件中。通常情况下,为保证 LSM 树中的所有条目都被检查到,在进行精确匹配查找或范围查找时,需要通过其索引结构访问每个组件 Ci。然而,也有一些优化方案可以将搜索范围限制在最初的一部分组件内。首先,如果通过生成逻辑确保了唯一索引值,例如时间戳保证唯一性,那么一旦在早期组件 Ci 中找到匹配值,查找即告完成。另一种情况是,如果查找条件使用了最近的时间戳值,那么目标条目还未迁移到最大的组件中时,可以限制我们的搜索范围。当合并游标循环穿过 (Ci, Ci+1) 组件对时,我们经常会有理由保留最近插入的条目(在过去 τi 秒内)在组件 Ci 中,仅允许较旧的条目转移到 Ci+1。如果最常见的查找是针对最近插入的值,则许多查找可以在 C0 树中完成,因此 C0 树发挥了重要的内存缓冲功能。这一点在 [23] 中也有所提及,并且是一个重要的效率考量。例如,在事务终止(abort)事件中访问短期事务 UNDO 日志的索引,创建后的一段相对较短时间内将有大量访问,我们可以预期大多数这些索引会留在内存中。通过记录每个事务的起始时间,我们可以确保所有在过去 τ0 秒内开始的事务日志都可以在 C0 组件中找到,而无需访问磁盘组件。2.3 LSM 树中的删除、更新和长延迟查找我们注意到,删除操作可以与插入操作共享推迟和批处理的宝贵属性。当一个索引行被删除时,如果在 C0 树的相应位置没有找到该键值条目,可以在该位置放置一个删除节点条目,同样以键值为索引,但该条目标记了一个删除的记录 ID(RID)。实际的删除操作可以在滚动合并过程中稍后进行,当实际的索引条目被遇到时:我们说删除节点条目会在合并过程中迁移到较大的组件中,并在遇到时将关联条目删除。与此同时,查找请求必须通过删除节点条目进行过滤,以避免返回已删除记录的引用。在查找相关的键值时,过滤操作很容易执行,因为删除节点条目将位于比该条目本身更早的组件的相应键值位置,并且在许多情况下,这种过滤会减少确定某条目已被删除的开销。在任何类型的应用程序中,记录更新导致索引值变化的情况都很少见,但如果我们将更新视为先删除再插入,LSM 树可以以推迟的方式处理此类更新。我们简要描述了另一种高效的索引修改操作。谓词删除(predicate deletion)是一种通过简单地断言谓词来执行批量删除的方法,例如,断言所有时间戳超过 20 天的索引值将被删除。当受影响的条目位于最旧(最大)的组件中,并在滚动合并的正常过程中变为驻留时,这种断言会导致它们在合并过程中被直接删除。另一种操作是长延迟查找(long-latency find),这为响应查询提供了一种高效的方法,其中结果可以等待最慢游标的循环周期。在组件 C0 中插入一个查找节点条目,查找操作实际上会在一个较长的时间段内进行,随着它向后续组件迁移。一旦查找节点条目已循环到 LSM 树中最大相关组件的适当区域,长延迟查找的累积记录 ID(RID)列表便完成。
-
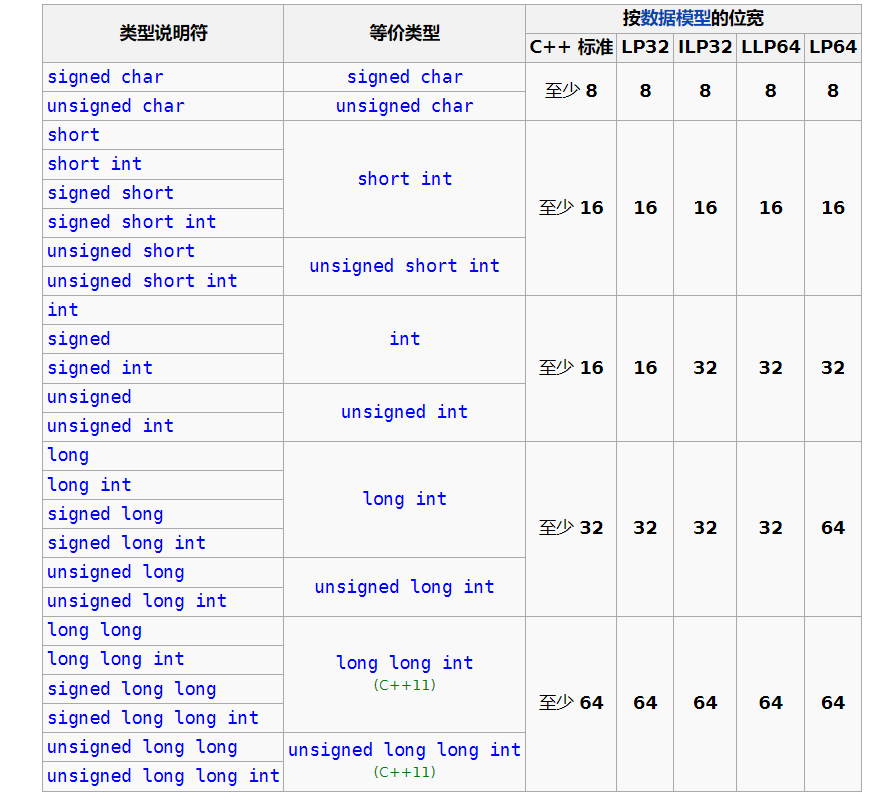
CPP基础教程 基本数据类型C++的基本数据类型有int, char, bool, short, long, long long, float, double, void, unsinged int(short, long long...), std::nullptr_t,具体可查types这么多都要记住?nullptr_t其实不用,其他的是的,不过这里给个建议,你只需要记住int, char, bool, long long, double, float, void这几个即可如果你需要无符号数那么在他们前边加上unsigned就好了。接下来对他们做个分类:整数浮点数intfloatlong longdoubleshort char和bool存储起来是按整数存的但是他们的作用并不是储存整数,所以我并没有把他们放在上边的表格里,char是字符类型可以存储ascii码表里所有的字符,bool是布尔类型用来存储true或false(在c++中我们判断条件应该用bool而不是整数01,当然他们会被转成bool类型,所以使用还是不影响的)接下来介绍一下它们的大小,直接上图这里有一个误区就是你在学习c语言课的时候可能老师跟你讲这个类型具体是多少多少字节,但是C++标准只规定了最少应该是几字节(上图显示为bit)并没有说具体就应该是几字节,所以在某些系统中你可以看到int居然是2字节?!什么这里short和int相同?long怎么在这是64位在那就32位了,这都是因为它们的大小是实现定义的,只规定了至少应该是多少位,而不是一定。(拓展:在以后开发时如果你不想因为数据大小造成困扰,那么就使用int_16, int_32, int_64类型的数据,这样就不用担心数据位宽不符合了)接下来就是他们能表示数的范围,对有符号整数来说N位有符号整数的最小保证范围从-(2^(N-1) - 1)到(2^(N-1) - 1),浮点数因为存储格式与整数不同,所以前边的结论并不适用于浮点数,浮点数存储结构大概是符号位 偏移 数据,这里我们假设符号位是0也就是正数,偏移是10(2),数据是101(2进制),那么这个数就是 110.1(2进制)也就是6.5,数据前补1,浮点从.101向后移动两位,所以浮点数可以表示远大于它的相同位宽的整数,但是数据会丢失精度,如果你需要高精度计算,千万别用浮点数这里还有一个误区就是char的表示范围(内部储存的整数)这也是实现定义的,有可能是-128到127也可能是0到255输入输出在c语言中标准输入输出就是scanf、printf,c++也支持这两个函数,不过更c++的写法是输入输出流即使用cin、cout,相比较来说各有优劣,这两套的区别就在格式化,看你是否需要格式化输入输出来选择合适的方法。cin、cout的用法如下#include <iostream> // 包含cin cout的头文件 using namespace std; // 这里是跟命名空间有关,这里先不讲 int main() { int a; cin >> a; // 这里>>是流操作符不是大于大于,代表将输入流中的数据传给a cout << a; // <<也是流操作符,这样你就可以看出流操作的方向,上边是cin流向a,这里是a流向cout return 0; }运行之后你输入几就会再输出几,如果你需要一次性输入更多变量(不需要格式化的,每个变量以空格或者回车结尾的),那么就可以直接这么写#include <iostream> using namespace std; int main() { int a, b; char c; cin >> a >> b >> c; // 输入 a b c cout << a << b << c; // 输出 a b c return 0; }还有一点,由于cin这套会和scanf这套同步缓冲池,所以cin这套的速度比scanf这套慢一倍,想要cin达到同样的性能可以直接解绑#include <iostream> int main() { std::ios::sync_with_stdio(false); std::cin.tie(0); // 上边两句就是解绑,使用之后你用cin读取的数据就不能通过printf输出了也就是不能混用了 }数组数组是一段相同类型的元素的集合,它们在逻辑上是连续的,在内存中也是连续的,数组的声明方式为类型 数组名[数组大小],例如我需要一个长度为10的int类型的叫arr数组,那么声明时就写int arr[10];,这个数组占的空间就是sizeof(int) * 10(这个sizeof 是关键字可以求后边类型所占字节),当我们需要访问数组中的某一个元素的时候,就需要通过下标访问,数组的下标是从0开始的,也就是说第一个元素的下标为0而不是1,第二个是1,以此类推,c/c++在你访问数组元素时并不会检查下标是否合理(在不在数组范围内),所以在操作数组时你需要严格控制操作的下标范围。当你需要一些类型相同的元素的时候就可以使用数组,比如说我要输入10个元素,如果你不会用数组的话那你可能会写int a, b, c, d, e...; cin >> a >> b >> c...;这很明显声明起来并不方便,10个元素还好如果是10000个呢?不能一个一个起名吧,这时候就可以使用数组int a[10000];搞定。不过这个时候输入输出就成了大问题,那么接下来就需要与循环结合起来,才能充分发挥数组的功能数组可以是多维的,例如二维数组可以声明为int arr[10][10];这样就得到了长10宽10的二维数组(不过他们在内存上还是连续的等同于int arr2[100]),当你需要访问第一行第二列的元素时就使用下标arr0;三维甚至更高维的数组同理循环选择结构C++的循环选择与C语言并没有区别,选择会用到if else switch,循环则有for、while、do while。用法如下:if (条件) 条件为true执行语句 else 条件为false执行语句else并不是必须的,看你自己需求,if和else后边都只接一条语句,需要接更多语句就需要使用大括号包围起来int a; cin >> a; if (a == 10) a = 5; cout << "a = 10\n"; else cout << "a != 10\n";思考一下上边的语句是否正确。看出问题了吗?没错这里的if后边其实只接了a = 5;这一条,else会找不到它对应的if,所以这时候会编译错误,去掉else之后cout << "a = 10\n";这句则是一定执行的所以千万要记得if else for while do后边接多个语句时要加大括号,原因可以看作用域这部分。所以上边代码的正确写法应该是:int a; cin >> a; if (a == 10) { a = 5; cout << "a = 10\n"; } else { cout << "a != 10\n"; } // 养成良好习惯,一句也加大括号有的人可能认为else if也是关键字什么的,其实不是,else if就是else语句后接了个if语句,本质上为if (condition) { blabla... } else { if () { blabla... } }for的使用形式为for(刚进入循环时执行一次的语句; 循环执行条件,为true才可以继续执行; 一次循环结束后执行的语句),没什么好讲的,直接上代码!int a[100]; for (int i = 0; i < 100; i++) { cin >> a[i]; } for (int i = 0; i < 100; i++) { cout << a[i]; }上边的代码做了什么事呢?首先是申明了一个大小为100的数组,之后在循环开始时申明了一个变量 i 并初始化为0,再判断i < 100为true,之后开始执行循环也就是cin >> a[i],循环体内所有语句执行完毕,自动执行i++,让i = 1...while的用法很简单,只有一个判断条件while(条件),条件为真则继续执行,使用while实现与上边for相同功能的写法是这样的:int a[100]; { int i = 0; while (i < 100) { cin >> a[i]; i++; } } { int i = 0; while (i < 100) { cout << a[i]; i++; } }为什么用了大括号呢,还是跟作用域有关,总之,while只有在条件为true时才继续执行,且不能像for一样在开始执行一次第一个‘;’前的语句dowhile和while类似,不同的是dowhile保证循环体代码至少执行一次,它是执行之后才判断条件真假,while和for则是一开始就判断do { cout << "13 * 4"; } while(false); // 记得不能忘了这个分号尽管上边的语句条件为false,但是仍然会输出“13 * 4”,这就是do while的特别之处continue break有的时候我们在循环体中可能想达到某些条件就提前退出或者不继续执行下边的代码,这时候就要用到continue、break控制了,continue的作用是跳过下边的代码,执行到循环尾也就是while (true) { a; continue; d; b; } <-这个地方 // 这是个死循环之后开始下一次循环,break是直接退出循环while (true) { a; break; d; b; } // 退出循环,不是死循环执行a之后就不会执行db了。那么实战中一般会怎么使用呢?,比如从0到100,输出所有奇数int a = 0; while (true) { if (a > 100) { break; } if (a % 1 == 0) { continue; } cout << a << ' '; }上边的例子即使用了break也使用了continue,你可以一步一步调试看看代码执行时发生了什么switch的功能有点鸡肋,你必须穷举所有结果,一般switch都跟break一起用,这就是为什么我在这才写switch,switch后边跟条件,但是与if不同,它不是判断真假,而是将条件进行匹配,这用到了另一个关键字caseint a; cin >> a; switch (a) { case 12: case 14: cout << "wow!\n"; break; default : cout << "emm..\n"; }上边的代码在输入12或者14时候会输出wow,其他情况都是emm..,这个例子同样表明不是所有case后都得跟break,如果不跟的话就会继续延顺下去,也就是说下边这种情况输入12时会输出good haha,输入14就是hahaint a; cin >> a; switch (a) { case 12: cout << "good " case 14: cout << "haha\n"; break; default : cout << "emm..\n"; }指针终于到了指针了,首先我要说明:指针一点也不难!指针也只是一个变量,它的标志就是类型中带有一个 * 号,比如int*就是int类型的指针,它可以指向一块类型为int的变量的内存,记住指针保存的就是地址就行了,这里不能理解的话那么我们抽象一下你是一个人,你叫做A,用代码表示就是人 A,你在这个地球上,你的位置(地址)是唯一的,因为不可能有人跟你重合,我们可以通过&得到你当前的位置比如经度117.42 纬度19.24 海拔345米,我们可以用一个叫人* pos = &A;来保存这个数据,同理,在程序运行时,每个变量也会有一个唯一的地址,这里不展开讨论,有兴趣的话自行了解,这个地址根据系统不同得到的结果也不同,64位系统就是64位数字32位系统就是32位数字,这个地址一定是整数,且是不会变的,我们可以通过这个地址找到这个变量的位置读取它或者修改它。int a{}; // a = 0 int *b = &a; // b = a 的地址 *b = 5; // a = 5,通过解引用修改b指向的那块地址的数据(a)的值 int c = *b; // c = 5,通过解引用读取b指向的a的值记住指针是一个变量,它保存的值是其他变量的地址,通过解引用就可以访问指针指向的变量。(*b)此刻就是a还有一点是数组与指针之间的关系,很多人都会搞错,先给出结论:数组和指针是完全不同的两个东西,唯一的关系就是数组可以退化成指针。int arr[100]; int* p = arr; // 也就是说,这句的意思不是数组和指针一样所以可以给p赋值arr,而是arr在这里退化成了指针,arr的地址储存在了p中 // 最简单的证明方法就是你不能给一个数组赋值指针,下边这句是不允许的 int* p2; int arr2[100] = p2;一个完整的数组包含了长度信息,而指针是不会包含这部分信息的。不过值得一提的是你可以对指针进行中括号运算。int arr[100]; int* p = arr; p[n] == arr[n] // 这个式子是恒成立的中括号运算本质上是通过指针 + 偏移计算元素位置,就是 p[n] 和 *(p + n)是等价的,所以你可以写出这样的代码0["ABC"]得到的结果是A。最后一小点,c++中的空指针默认为nullptr而不是NULLnullptr就是最开始提到的std::nullptr类型的数据,在写c++代码时,如果你要表示空指针,请用nullptr而不是NULL或者0。函数函数的作用是增加代码复用,因为有的句子你可能会重复写很多次,假如有的功能要几百行几千行,你又需要多次使用该功能,总不能一遍又一遍写吧,哪怕复制粘贴也是需要改一些参数的,还是很麻烦,所以这时候就可以通过函数包装一下。一个完整的函数需要 返回值类型 函数名 (函数参数) { 执行代码; 返回值;(返回类型为void时不需要返回值,但是可以通过return提前结束函数执行)}举个简单的例子int add(int a, int b) { return a + b; } int main() { std::cout << add(3, 4); // 输出7 }C++的函数可以通过修改参数进行重载,以下是一些例子(1) int a() { ... return ...; } // 先声明函数a (2) double a() { } // 错误,修改返回值类型不能重载函数 (3) int a(int x) { ... } // 没问题,这个函数a比(1)多了一个int参数 (4) double a(double x) { ... } // 没问题,(4)和(3)的参数类型不同 (5) double a(int x) { ... } // 错误,参数类型和(3)冲突 (6) int a(int x, double y) { ... } // 没问题 (7) int a(double x, int y) { ... } // 没问题,和(6)不冲突,参数虽然数量一样,但是对应参数类型不同重载函数之后在执行函数时程序会选择最匹配的函数执行(1) int a(int x) { ... } int main() { a(3.14) // 可以执行a函数,但是3.14会被转为整型也就是 3 } ------------------------------------------------------ (2) int a(int x) { ... return 1; } int a(double x) { ... return 2; } int main() { a(3.14); // 返回2 a(3); // 返回1 }函数的参数是复制进去的,所以如果你需要修改一些数据,是不能通过直接传参完成的void fun(int a) { a = 10; } int main() { int b = 89; fun(b); /** b这时候还是89,不会在fun中被修改为10 这是因为在调用fun函数时,我们执行的操作是将b赋值给a,这时候a就是一个和b完全无关的变量 对a执行任何操作都与b无关 **/ }想要修改b为10,我们有两种做法,第一种做法是通过指针来修改,如我前文所说,通过指针可以找到变量本身,这样我们修改的就是我们想要的变量,而不是一个通过复制得到的变量。void fun(int* a) { *a = 10; } int main() { int b = 89; fun(&b); // ok, 现在b = 10 }开始讲第二种方法前,我们再引入一个新的概念引用,引用说简单点就是变量的别名,小花有一个别名叫张三,有的人喜欢叫小花,有的人喜欢叫张三,虽然名字不一样,但是表示的还是同一个人,引用就是这样的,你可以通过给一个变量起别名来访问该变量。引用的声明方式是在类型后加一个&(&作用真多...)int a; int &b = a; // b是a的别名 int &c = a; // c、b都是a的别名 int &d; // 错误,引用在申明时就得初始化!!! b = 10; // a,b,c都等于10引用作为函数参数时,可以直接修改原数据void fun(int &a) { a = 10; } int main() { int a; fun(a); // a = 10 }作用域与生命周期这一部分我觉得是非常简单的,总结起来就一句话一对大括号内的内容属于一个作用域,变量的生命周期从申明开始到离开大括号结束,全局变量、静态变量生命周期贯穿整个程序。举例子:1. void f() { 2. int a; 3. int b; 4. { 5. int c; 6. std::cin >> c; 7. } 8. std::cin >> c; 9. int c; 10. }想想上边的代码有问题吗?如果有那是第几行?这个函数中我们声明了两次变量c,错误点在这吗?当然不是。我们把1-10行叫作用域1,4-7行叫作用域2,我们先在作用域2声明了c并使用cin输入c。在离开作用域2之后又再一次尝试输入变量c,这时候就有问题了,离开了作用域2,变量c的生命周期结束,这时候在cin时不可以的,因为不知道c是啥,所以错误点在第8行。变量ab的生命周期一直到函数执行完毕。你可以自己写一些例子实验一下,亲自体会一下生命周期、作用域。
-
[6.5840]Lab 1: MapReduce翻译 引言在本实验中,您将构建一个 MapReduce 系统。您将实现一个工作进程,该进程调用应用程序的 Map 和 Reduce 函数,并处理文件的读取和写入;同时,您还将实现一个coordinator进程,该进程将任务分配给工作进程,并处理失败的工作进程。您将构建的系统类似于 MapReduce论文中的描述。(注意:本实验中使用“coordinator”一词,而不是论文中的“主节点”)。开始您需要设置 Go 环境以进行实验。使用 git(一个版本控制系统)获取初始实验软件。要了解更多关于 git 的信息,请查看Pro Git Book或 git 用户手册。$ git clone git://g.csail.mit.edu/6.5840-golabs-2024 6.5840 $ cd 6.5840 $ ls Makefile src我们为您提供了一个简单的顺序 MapReduce 实现,位于 src/main/mrsequential.go。该实现一次运行一个 Map 和一个 Reduce,均在单个进程中执行。我们还为您提供了一些 MapReduce 应用程序:在 mrapps/wc.go 中的词频统计和在 mrapps/indexer.go 中的文本索引器。您可以按如下方式顺序运行词频统计:$ cd ~/6.5840 $ cd src/main $ go build -buildmode=plugin ../mrapps/wc.go $ rm mr-out* $ go run mrsequential.go wc.so pg*.txt $ more mr-out-0 A 509 ABOUT 2 ACT 8 ...mrsequential.go 的输出保存在文件 mr-out-0 中。输入来自名为 pg-xxx.txt 的文本文件。请随意借用 mrsequential.go 中的代码。您还应该查看 mrapps/wc.go 以了解 MapReduce 应用程序代码的样子。在本实验和所有其他实验中,我们可能会对提供给您的代码进行更新。为了确保您能够获取这些更新并使用 git pull 轻松合并它们,最好将我们提供的代码保留在原始文件中。您可以按照实验说明对我们提供的代码进行修改;只是不要移动它。您可以在新文件中添加自己的新函数。您的任务(中等/困难)您的任务是实现一个分布式 MapReduce 系统,包括两个程序:coordinator和worker。只有一个coordinator进程,和一个或多个并行执行的worker进程。在实际系统中,worker将运行在不同的机器上,但在本实验中,您将在单台机器上运行所有worker。worker将通过 RPC 与coordinator进行通信。每个worker进程将循环执行以下步骤:请求coordinator分配任务,从一个或多个文件中读取任务输入,执行任务,将任务输出写入一个或多个文件,然后再次请求coordinator分配新任务。coordinator应注意到如果某个worker在合理的时间内(在本实验中为十秒)未完成其任务,则将相同的任务分配给其他worker。我们为您提供了一些初始代码。coordinator和worker的“main”例程位于 main/mrcoordinator.go 和 main/mrworker.go 中;请不要更改这些文件。您应将实现代码放入 mr/coordinator.go、mr/worker.go 和 mr/rpc.go 文件中。如何运行代码以下是如何在词频统计 MapReduce 应用程序上运行您的代码的步骤。首先,确保词频统计插件是最新构建的:$ go build -buildmode=plugin ../mrapps/wc.go在主目录中,运行coordinator:$ rm mr-out* $ go run mrcoordinator.go pg-*.txtmrcoordinator.go 的 pg-*.txt 参数是输入文件;每个文件对应一个“拆分”,是一个 Map 任务的输入。在一个或多个其他窗口中,运行worker:$ go run mrworker.go wc.so当worker和coordinator完成后,查看输出文件 mr-out-*。当您完成实验后,输出文件的排序并合并内容应与顺序输出匹配,如下所示:$ cat mr-out-* | sort | more A 509 ABOUT 2 ACT 8 ...我们在 main/test-mr.sh 中提供了一个测试脚本。测试检查词频统计和索引器 MapReduce 应用程序在给定 pg-xxx.txt 文件作为输入时是否产生正确的输出。测试还检查您的实现是否以并行方式运行 Map 和 Reduce 任务,以及您的实现是否能够从运行任务时崩溃的worker中恢复。如果您现在运行测试脚本,它会挂起,因为coordinator从未完成:$ cd ~/6.5840/src/main $ bash test-mr.sh *** Starting wc test.您可以将 ret := false 更改为 true,在 mr/coordinator.go 的 Done 函数中,这样coordinator会立即退出。然后:$ bash test-mr.sh *** Starting wc test. sort: No such file or directory cmp: EOF on mr-wc-all --- wc output is not the same as mr-correct-wc.txt --- wc test: FAIL测试脚本期望看到名为 mr-out-X 的文件输出,每个文件对应一个 Reduce 任务。mr/coordinator.go 和 mr/worker.go 的空实现不会生成这些文件(或执行其他操作),因此测试失败。当您完成时,测试脚本的输出应如下所示:$ bash test-mr.sh *** Starting wc test. --- wc test: PASS *** Starting indexer test. --- indexer test: PASS *** Starting map parallelism test. --- map parallelism test: PASS *** Starting reduce parallelism test. --- reduce parallelism test: PASS *** Starting job count test. --- job count test: PASS *** Starting early exit test. --- early exit test: PASS *** Starting crash test. --- crash test: PASS *** PASSED ALL TESTS您可能会看到一些来自 Go RPC 包的错误消息,比如:{alert type="info"}2019/12/16 13:27:09 rpc.Register: method "Done" has 1 input parameters; needs exactly three{/alert}忽略这些消息;注册coordinator作为 RPC 服务器会检查其所有方法是否适合 RPC(具有 3 个输入参数);我们知道 Done 方法不是通过 RPC 调用的。此外,根据您终止工作进程的策略,您可能会看到一些形式的错误:{alert type="info"}2024/02/11 16:21:32 dialing:dial unix /var/tmp/5840-mr-501: connect: connection refused{/alert}在测试结束后看到这些消息是正常的;它们是在worker无法在coordinator退出后联系到 RPC 服务器时产生的。几条规则:映射阶段:映射阶段应将中间键分成多个桶,供 nReduce 减缩任务使用,其中 nReduce 是减缩任务的数量,也就是 main/mrcoordinator.go 传递给 MakeCoordinator() 的参数。 每个映射器应创建 nReduce 中间文件,供还原任务使用。worker实现:Worker 实现应将第 X 个 reduce 任务的输出放到 mr-out-X 文件中。mr-out-X 文件应包含每个 Reduce 函数输出的一行。 这一行应该以 Go 的"%v %v "格式生成,并以键和值调用。 请查看 main/mrsequential.go 中注释为 "this is the correct format"的一行。 如果您的实现与此格式偏差过大,测试脚本就会失败。可修改的文件:您可以修改 mr/worker.go、mr/coordinator.go 和 mr/rpc.go。您可以暂时修改其他文件进行测试,但确保您的代码在原始版本中也能正常工作;我们将使用原始版本进行测试。中间输出文件:Worker应将中间 Map 输出放入当前目录的文件中,以便后续将其作为输入供 Reduce 任务使用。完成标志:main/mrcoordinator.go 期望 mr/coordinator.go 实现一个 Done() 方法,当 MapReduce 作业完全完成时返回 true;此时,mrcoordinator.go 将退出。worker退出:当作业完全结束时,Worker 进程应退出。实现这一点的简单方法是使用 call() 的返回值:如果 Worker 无法联系到 Coordinator,则可以假设 Coordinator 已退出,因为作业已完成,因此 Worker 也可以终止。根据您的设计,您可能还会发现有一个“请退出”的伪任务是有帮助的,Coordinator可以将其分配给 Worker。提示:指南页面提供了一些开发和调试的提示。一个启动的方式是修改 mr/worker.go 的 Worker() 函数,向 Coordinator 发送 RPC 请求任务。然后修改 Coordinator 以响应尚未开始的 Map 任务的文件名。接着修改 worker 以读取该文件并调用应用的 Map 函数,方式类似于 mrsequential.go。应用的 Map 和 Reduce 函数在运行时使用 Go 插件包加载文件名以 .so 结尾的文件。如果您在 mr/ 目录中更改任何内容,您可能需要重构所有您使用的 MapReduce 插件,例如:go build -buildmode=plugin ../mrapps/wc.go。本实验依赖于 Worker 共享文件系统。当所有 Worker 在同一台机器上运行时,这很简单,但如果 Worker 在不同机器上运行,则需要全局文件系统,如 GFS。中间文件的合理命名约定是 mr-X-Y,其中 X 是 Map 任务编号,Y 是减少任务编号。Worker的 Map 任务代码需要在文件中储存中间键/值对, 让 Reduce 任务可以正确读取。一种可行的方式是使用 Go 的 encoding/json 包。可以使用以下方式将键/值对以 JSON 格式写入打开的文件:enc := json.NewEncoder(file) for _, kv := ... { err := enc.Encode(&kv)并以此方式读取该文件:dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) }Worker的映射部分可以使用 ihash(key) 函数(在 worker.go 中)来选择给定键的 Reduce 任务。您可以从 mrsequential.go 中复制一些代码,用于读取 Map 输入文件、在 Map 和 Reduce 之间对中间键/值对进行排序,以及将 Reduce 输出存储到文件中。coordinator作为一个 RPC 服务器将是并发的;不要忘记锁定共享数据。使用 Go 的竞争检测器,命令为 go run -race。test-mr.sh 的开头有一条注释,告诉您如何使用 -race 运行它。当我们对您的实验评分时,不会使用竞争检测器。然而,如果您的代码存在竞争条件,那么在我们不使用竞争检测器的情况下测试时,您的代码很可能会失败。Worker 有时需要等待,例如,直到最后一个映射完成前,Reduce 任务是无法开始的。一个可行的方案是 Worker 定期向 Coordinator 请求工作,在每个请求之间使用 time.Sleep() 进行休眠。另一种可行方案是 Coordinator 中相关的 RPC 处理程序有一个循环等待,使用 time.Sleep() 或 sync.Cond。Go 为每个 RPC 在自己的线程中运行处理程序,因此某个处理程序在等待并不妨碍 Coordinator 处理其他 RPC。Coordinator无法可靠地区分崩溃的 Worker、由于某种原因停滞的存活 Worker,以及执行但速度过慢以至于无用的 Worker。您能做的最好的事情是让 Coordinator等待一段时间,然后放弃并将任务重新分配给其他 Worker。在本实验中,让 Coordinator等待十秒;之后 Coordinator应假设 Worker已死亡(当然,它也可能没有)。如果您选择实现备份任务(第3.6节),请注意我们测试您的代码在 Worker 执行任务而不崩溃时不会调度多余的任务。备份任务应仅在相对较长的时间段后调度(例如,10秒)。要测试崩溃恢复,您可以使用 mrapps/crash.go 应用插件。它会在 Map 和 Reduce 函数中随机退出。为了确保没有人观察到在崩溃情况下部分写入的文件,MapReduce 论文提到了一种使用临时文件的技巧,并在完全写入后原子性地重命名。您可以使用 ioutil.TempFile(如果您运行的是 Go 1.17 或更高版本,则使用 os.CreateTemp)创建临时文件,并使用 os.Rename 原子性地重命名它。test-mr.sh 在子目录 mr-tmp 中运行所有进程,因此如果出现问题并且您想查看中间或输出文件,请查看那里。随意暂时修改 test-mr.sh,在失败的测试后退出,以便脚本不继续测试(并覆盖输出文件)。test-mr-many.sh 多次运行 test-mr.sh,您可能希望这样做以发现低概率的错误。它接受一个参数,即运行测试的次数。您不应并行运行多个 test-mr.sh 实例,因为协调者将重用相同的套接字,导致冲突。Go RPC 仅发送名称以大写字母开头的结构字段。子结构也必须具有大写字段名称。当调用 RPC 的 call() 函数时,回复结构应包含所有默认值。RPC 调用应如下所示:reply := SomeType{} call(..., &reply)在调用之前不应设置 reply 的任何字段。如果您传递的回复结构具有非默认字段,则 RPC 系统可能会默默返回错误值。
-
[C++QUIZ]#251 #243 251#include <iostream> template<class T> void f(T) { std::cout << 1; } template<> void f<>(int*) { std::cout << 2; } template<class T> void f(T*) { std::cout << 3; } int main() { int *p = nullptr; f( p ); }{card-describe title="输出"}3{/card-describe}{callout color="#f0ad4e"}这道题没有那么简单的, 也让我更了解模板首先在模板解析时不考虑特化版本, 所以这里有两个重载void f(T)和void f(T*), 很简单的我们的p匹配的应该是void f(T*)这是毋庸置疑的, 因为第二个比第一个更能描述参数特征那么按理说特化版本的void f<>(int*)才是最匹配的, 这里为什么不输出2呢?这里需要搞清楚一件事void f<>(int*)是哪个模板的特化标准中提到了A declaration of a function template (...) being explicitly specialized shall precede the declaration of the explicit specialization.说明我们应该先有模板再有特化, void f<>(int*)是在void f(T*)之前的. 所以void f<>(int*)是void f(T)的特化, 在第一次的选择中void f(T)已经被淘汰, 故也不选择它的特化版本void f<>(int*), 所以输出3{/callout}243#include <iostream> template <typename T> struct A { static_assert(T::value); }; struct B { static constexpr bool value = false; }; int main() { A<B>* a; std::cout << 1; } {card-describe title="输出"}1{/card-describe}{callout color="#f0ad4e"}第一眼static_assert(false)秒了, 然后错误在这个例子中, A<B>如果被实例化, 那么显然是不能编译通过的, 在程序中并没有出现显式特化或者显式实例化, 那么接下来考虑的就是有没有出现隐式实例化这里的A<B>仅仅是指针而不需要对应类型的对象, 所以也没有被隐式实例化, 故可以输出1你可以看到有没有A<B>* a这行生成的汇编都一样{/callout}
![[doris]doris笔记](http://www.koarz.top/usr/themes/Joe/assets/thumb/17.jpg)
![[论文]The Log-Structured Merge-Tree (LSM-Tree)翻译](https://i.072333.xyz/file/AgACAgEAAyEGAASMaMWHAAIL5mczdqajMbJ-9QABaH4SjRnyDFnOWgACGq8xGzn0oEVSGGHO0U_uewEAAwIAA3gAAzYE.png)
![[6.5840]Lab 1: MapReduce翻译](http://www.koarz.top/usr/themes/Joe/assets/thumb/41.jpg)
![[C++QUIZ]#251 #243](https://a.koarz.top/usr/uploads/2024/07/3247274755.png)